Transcription par lot
Source: 09_batch_transcription
Lit un fichier audio local, l’envoie à l’API OpenAI Whisper en une seule fois, et écrit la transcription dans un fichier texte. Contrairement à l’exemple de transcription locale, aucun modèle n’a besoin d’être téléchargé ; le fichier audio complet est envoyé et un seul bloc de transcription est reçu en retour.
Exécution
melodium run 09_batch_transcription/Compo.toml \
--input meeting.wav \
--openai_key sk-...openai_key est une clé d’API OpenAI .
[…] info: stt: reading audio file…
[…] info: stt: transcription completeFonctionnement
Stt encapsule RemoteStt avec un backend et un modèle fixes :
model Stt(const openai_key: string) : RemoteStt {
backend = "openai"
api_key = |wrap<string>(openai_key)
base_url = ""
model = "whisper-1"
}startup déclenche readLocal, dont la sortie alimente directement transcribe :
treatment main(
const input: string,
const output: string = "transcript.txt",
const openai_key: string
)
model stt: Stt(openai_key=openai_key)
{
startup()
logStart: logInfoMessage(label="stt", message="reading audio file…")
startup.trigger -> logStart.trigger
read: readLocal(path=input)
startup.trigger -> read.trigger
readFailed: logErrorMessage(label="read", message="audio file could not be read")
readErrors: logErrors(label="read")
read.failed -> readFailed.trigger
read.errors -> readErrors.messages
transcribe[stt=stt]()
read.data -> transcribe.audio
sttFailed: logErrorMessage(label="stt", message="transcription failed")
sttError: logError(label="stt")
transcribe.failed -> sttFailed.trigger
transcribe.error -> sttError.message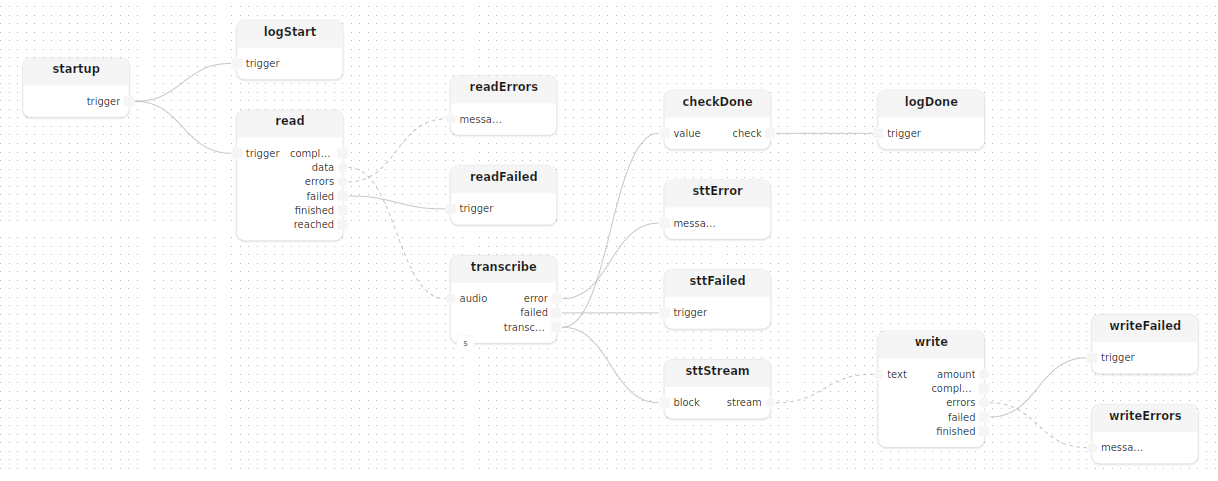
Pont Block/Stream
transcribe.transcript est un Block<string>, une seule valeur émise une fois la transcription complète prête. Deux opérations en aval la consomment, nécessitant deux adaptateurs différents :
logDone: logInfoMessage(label="stt", message="transcription complete")
checkDone: check<string>()
sttStream: stream<string>()
write: writeTextLocal(path=output)
transcribe.transcript --> checkDone.value,check -> logDone.trigger
transcribe.transcript --> sttStream.block,stream -> write.text
writeFailed: logErrorMessage(label="write", message="output write failed")
writeErrors: logErrors(label="write")
write.failed -> writeFailed.trigger
write.errors -> writeErrors.messages
}check<string>()rejette la valeur de chaîne et émetBlock<void>, utilisé uniquement pour déclencher le logstream<string>()convertit leBlock<string>enStream<string>quewriteTextLocalpeut consommer
Le fan-out --> alimente les deux branches simultanément à partir du même bloc transcript.
Dépendances
[dependencies]
std = "0.10.1" # flux de base, journalisation, structures de données
fs = "0.10.1" # lecture/écriture de fichiers locaux
ml = "0.10.1" # inférence LLM, STT, TTS et modèles locaux