Serveur de chat LLM
Un serveur HTTP qui accepte des prompts en texte brut via POST /chat et renvoie la réponse du LLM token par token en flux. La connexion au LLM est déclarée comme modèle et partagée entre toutes les requêtes concurrentes.
Exécution
melodium run 01_text_llm_chat/Compo.toml --api_key sk-... --model claude-sonnet-4-6api_key est ici une clé d’API Anthropic , puisque model est défini sur un modèle Claude.
$ curl -X POST http://127.0.0.1:8080/chat -d "What is Mélodium?"
Mélodium is a dataflow programming language…Fonctionnement
ChatLlm encapsule RemoteLlm avec un backend, un system prompt et une limite de tokens fixes :
model ChatLlm(const api_key: string, const model: string) : RemoteLlm {
backend = "anthropic"
api_key = |wrap<string>(api_key)
base_url = ""
model = model
system = "You are a helpful assistant. Answer concisely."
max_tokens = 512
temperature = _
top_p = _
timeout = _
}Le champ backend sélectionne le fournisseur ("anthropic", "openai", etc.) ; changer de fournisseur revient uniquement à modifier backend et model dans la définition du modèle. Le reste du pipeline n’est pas affecté.
Deux modèles sont instanciés au démarrage : le HttpServer et ChatLlm. Le traitement startup se déclenche une fois au lancement du programme, et son trigger est transmis à la fois à start (qui lie le socket du serveur) et au message de log de démarrage :
treatment main(
const api_key: string,
const model: string = "claude-sonnet-4-6",
const port: u16 = 8080
)
model server: HttpServer(host=|from_ipv4(|localhost_ipv4()), port=port)
model llm: ChatLlm(api_key=api_key, model=model)
{
startup()
start[http_server=server]()
logStarted: logInfoMessage(label="server", message="LLM chat server started")
startup.trigger -> start.trigger
startup.trigger -> logStarted.trigger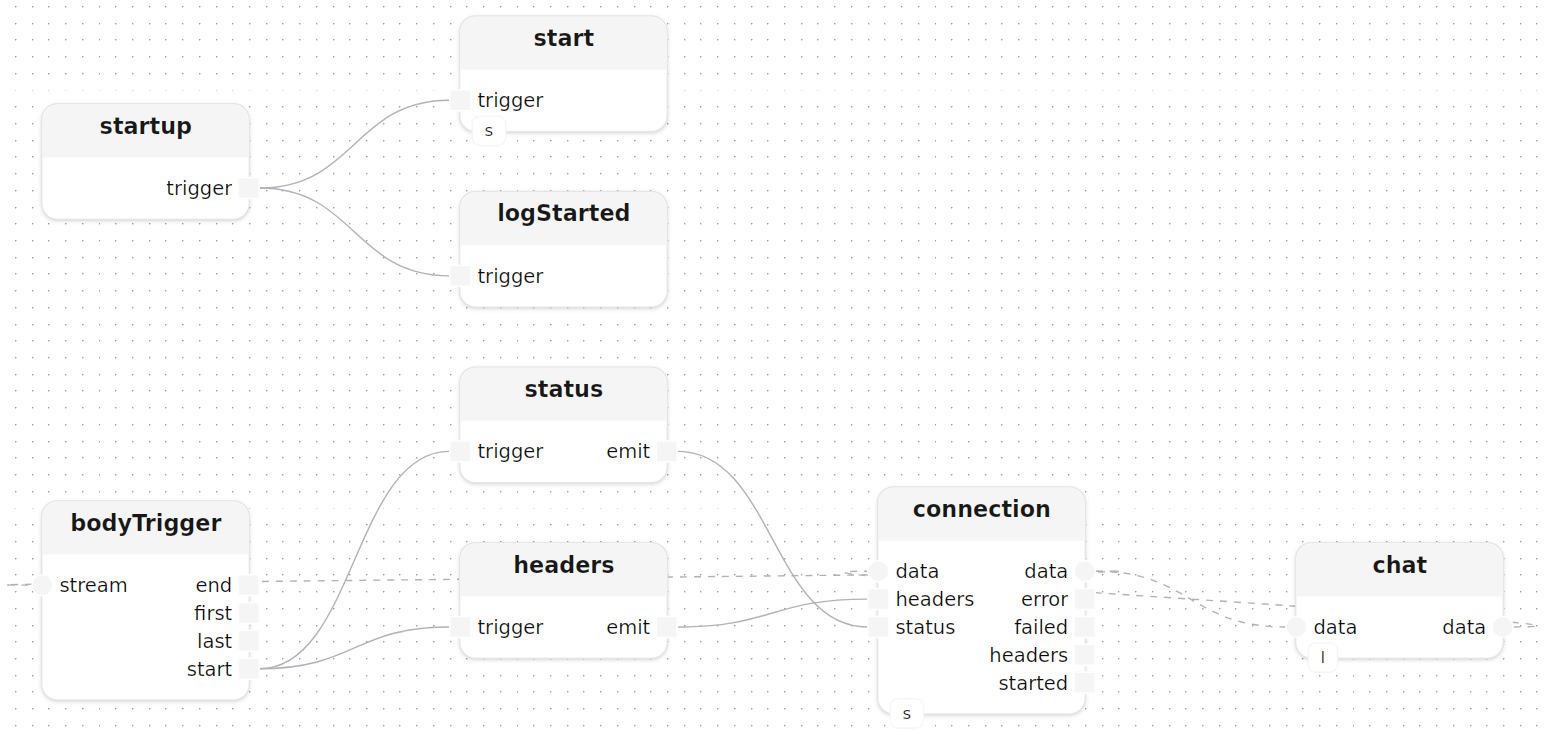
Envoyer le statut et les en-têtes avant lecture du corps
Chaque connection a besoin d’un statut et d’en-têtes envoyés avant que le corps de la réponse ne commence à être diffusé. bodyTrigger se déclenche dès l’arrivée du premier octet de la requête, et ce signal Block<void> unique se propage simultanément vers status et headers via emit et trigger :
connection[http_server=server](method=|post(), route="/chat")
status: emit<HttpStatus>(value=|ok())
headers: emit<StringMap>(value=|map([]))
bodyTrigger: trigger<byte>()
connection.data -> bodyTrigger.stream,start --> status.trigger,emit -> connection.status
bodyTrigger.start --------> headers.trigger,emit -> connection.headers
chat[llm=llm]()
connection.data -> chat.data,data -> connection.dataLe sous-traitement chat
Chaque connexion entrante est traitée par le sous-traitement chat, qui est un pipeline direct en trois étapes :
treatment chat[llm: RemoteLlm]()
input data: Stream<byte>
output data: Stream<byte>
{
decode()
llmStream[llm=llm]()
encode()
llmPrompt: logInfos(label="llm")
llmErrors: logErrors(label="llm")
Self.data -> decode.data,text -> llmStream.prompt,token -> encode.text,data -> Self.data
decode.text -> llmPrompt.messages
llmStream.error -> llmErrors.messages
}decodeconvertit les octets bruts de la requête en texte UTF-8llmStreamenvoie le texte comme prompt et émet les tokens sous forme deStream<string>à mesure qu’ils arriventencodeconvertit chaque token en octets et les transmet directement dansconnection.data
Comme llmStream émet les tokens en flux, ils atteignent la réponse HTTP au fur et à mesure de leur production, sans tampon et sans logique asynchrone explicite.
Le texte du prompt et les erreurs LLM sont transmis indépendamment aux loggers (logInfos, logErrors) via des connexions séparées, sans interrompre le flux de tokens.
Explication vidéo
Dépendances
[dependencies]
std = "0.10.1" # flux de base, journalisation, structures de données
http = "0.10.1" # serveur et client HTTP
net = "0.10.1" # utilitaires d'adresses IP
encoding = "0.10.1" # encodage / décodage UTF-8
ml = "0.10.1" # inférence LLM, STT, TTS et modèles locaux