Assistant vocal temps réel
Source: 11_realtime_voice_assistant
Un assistant vocal qui transcrit l’audio du microphone avec Whisper local et envoie chaque segment à un modèle de langage pour obtenir une réponse. Deux points d’entrée permettent de choisir entre un LLM distant (tokens en flux) ou un Mistral 7B entièrement local (pas de clé d’API).
Exécution
Avec un LLM distant (GPT-4o) :
melodium run 11_realtime_voice_assistant/Compo.toml --openai_key sk-...openai_key est une clé d’API OpenAI .
Entièrement local (pas de clé d’API, nécessite ~14 Go de RAM) :
melodium run 11_realtime_voice_assistant/Compo.toml localonly[…] info: assistant: ready, speak into the microphone
[…] info: you: What time is it in Tokyo?
[…] info: assistant: Tokyo est en heure standard du Japon (JST), soit UTC+9…Fonctionnement
Les deux points d’entrée partagent la même séquence de chargement Whisper et les mêmes modèles :
model WhisperHub() : HfHub { repo_id = "openai/whisper-tiny" }
model Asr() : Whisper {}La différence réside uniquement dans le backend LLM utilisé en aval.
main : Whisper local + LLM distant
Le LLM distant est un modèle RemoteLlm configuré pour GPT-4o avec un system prompt court et concis :
model RemoteAssistant(const openai_key: string) : RemoteLlm {
backend = "openai"
api_key = |wrap<string>(openai_key)
base_url = ""
model = "gpt-4o"
system = "You are a concise voice assistant. Answer in plain text, one short paragraph."
max_tokens = |wrap<u64>(256)
temperature = |wrap<f32>(0.6)
top_p = _
timeout = _
}main récupère et charge Whisper en premier, puis ne démarre l’enregistrement qu’une fois le chargement terminé :
treatment main(const openai_key: string)
model whisperHub: WhisperHub()
model asr: Asr()
model llm: RemoteAssistant(openai_key=openai_key)
{
fetchAsr: fetch[hub=whisperHub]()
loadAsr: loadWhisper[whisper=asr]()
startup.trigger -> fetchAsr.trigger
fetchAsr.safetensors -> loadAsr.safetensors
fetchAsr.tokenizer -> loadAsr.tokenizer
record: recordMono(device=_, sample_rate=_)
asrDecode: decode[whisper=asr]()
loadAsr.loaded -> record.trigger
loadAsr.loaded -> asrDecode.ready
record.signal -> asrDecode.audio
}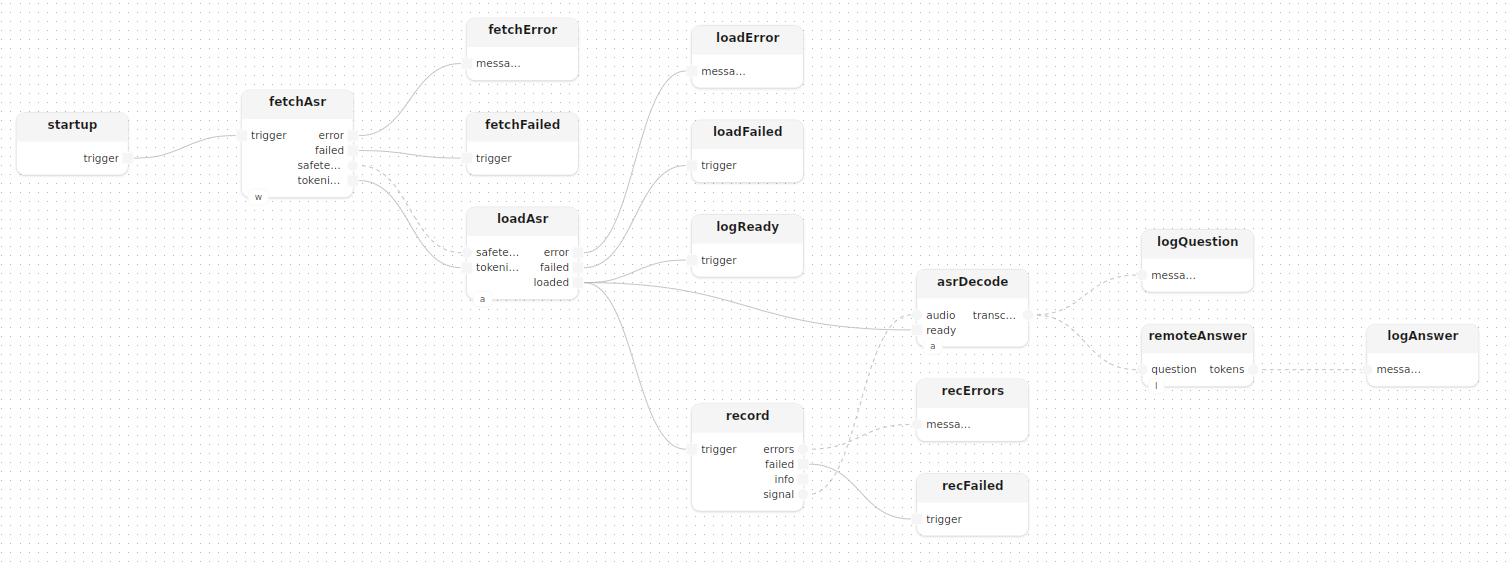
Chaque segment transcrit est transmis en fan-out à deux consommateurs simultanément :
asrDecode.transcribed -> logQuestion.messages
asrDecode.transcribed -> remoteAnswer.questionremoteAnswer[llm: RemoteLlm] enveloppe la question dans "[Question] {q}" et appelle llmStream, qui émet les tokens un par un en tant que Stream<string>, affichés dans le journal en temps réel sans attendre la réponse complète :
treatment remoteAnswer[llm: RemoteLlm]()
input question: Stream<string>
output tokens: Stream<string>
{
wrapEntry: entry(key="q")
fmt: format(format="[Question] {q}")
llmStream[llm=llm]()
Self.question -> wrapEntry.value,map -> fmt.entries,formatted -> llmStream.prompt,token -> Self.tokens
}localonly : Whisper local + Mistral local
Le point d’entrée localOnly ajoute deux modèles supplémentaires pour un backend Mistral 7B entièrement local :
model MistralHub() : HfHub { repo_id = "mistralai/Mistral-7B-v0.1" }
model LocalLlm() : Mistral {
temperature = 0.7
top_p = 0.9
max_new_tokens = 200
}Whisper et Mistral sont récupérés en parallèle depuis startup, et se chargent indépendamment :
treatment localOnly()
model whisperHub: WhisperHub()
model mistralHub: MistralHub()
model asr: Asr()
model llm: LocalLlm()
{
fetchAsr: fetch[hub=whisperHub]()
fetchLlm: fetch[hub=mistralHub]()
loadAsr: loadWhisper[whisper=asr]()
loadLlm: loadMistral[mistral=llm]()
startup.trigger -> fetchAsr.trigger
startup.trigger -> fetchLlm.trigger
fetchAsr.safetensors -> loadAsr.safetensors
fetchAsr.tokenizer -> loadAsr.tokenizer
fetchLlm.safetensors -> loadLlm.safetensors
fetchLlm.tokenizer -> loadLlm.tokenizer
}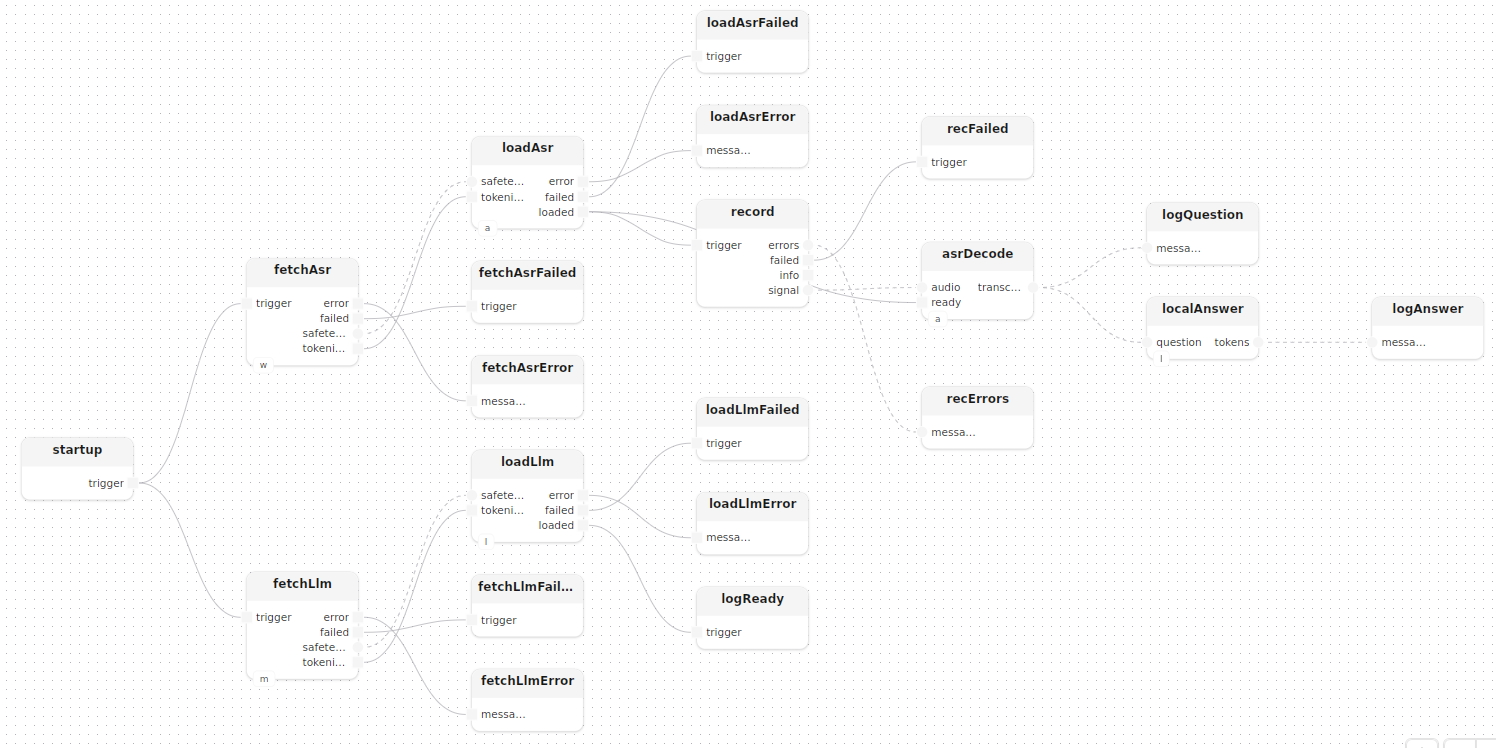
L’enregistrement démarre dès que Whisper est chargé (loadAsr.loaded), ce qui peut arriver avant que Mistral ait fini de charger ; chaque segment transcrit est tout de même transmis à localAnswer[llm: Mistral], qui le formate dans le style d’instruction de Mistral et appelle generate au lieu de llmStream :
treatment localAnswer[llm: Mistral]()
input question: Stream<string>
output tokens: Stream<string>
{
wrapEntry: entry(key="q")
fmt: format(format="[INST] {q} [/INST]")
generate[mistral=llm]()
Self.question -> wrapEntry.value,map -> fmt.entries,formatted -> generate.prompt,generated -> Self.tokens
}Interface partagée, backends différents
remoteAnswer et localAnswer exposent tous deux la même interface question: Stream<string> en entrée / tokens: Stream<string> en sortie, ce qui rend la logique de fan-out et de journalisation identique dans chaque point d’entrée. Le point d’entrée ne sait pas et n’a pas besoin de savoir lequel il appelle ; changer de backend est purement une préoccupation au niveau du modèle.
Dépendances
[dependencies]
std = "0.10.1" # flux de base, journalisation, structures de données
audio = "0.10.1" # décodage / encodage / rééchantillonnage audio
record = "0.10.1" # capture microphone
ml = "0.10.1" # inférence LLM, STT, TTS et modèles locaux