Transcription vocale
Source: 02_speech_transcription
Transcrit de l’audio en texte à l’aide d’un modèle Whisper local téléchargé automatiquement depuis Hugging Face au premier lancement. Deux points d’entrée : main pour l’entrée microphone en direct, fromfile pour transcrire un fichier audio existant.
Exécution
Transcription en direct depuis le microphone :
melodium run 02_speech_transcription/Compo.tomlTranscrire un fichier audio :
melodium run 02_speech_transcription/Compo.toml fromfile -- --input_file speech.wavSortie attendue :
[…] info: transcription: Hello, this is a test.
[…] info: transcription: The model is running locally.Fonctionnement
Deux modèles sont déclarés en tête de chaque point d’entrée :
model Hub() : HfHub { repo_id = "openai/whisper-tiny" }
model Speech() : Whisper {}Hub pointe vers le dépôt HfHub pour Whisper tiny. Speech est une configuration Whisper vide ; les paramètres par défaut sont utilisés.
Séquence de chargement du modèle
Les connexions garantissent que la capture audio ne démarre qu’une fois le modèle prêt :
treatment main(const output: string = "transcription.txt")
model hub: Hub()
model whisper: Speech()
{
startup()
fetch[hub=hub]()
load[whisper=whisper]()
decode[whisper=whisper]()
record: recordMono(device=_, sample_rate=_)
log: logInfos(label="transcription")
write: writeTextLocal(path=output, append=true)
startup.trigger -> fetch.trigger
fetch.safetensors -> load.safetensors
fetch.tokenizer -> load.tokenizer
load.loaded -> decode.ready
load.loaded -> record.trigger
record.signal -> decode.audiostartup déclenche fetch, qui télécharge les poids et le tokenizer ; load initialise le modèle ; load.loaded conditionne simultanément decode.ready et la source audio. Aucune primitive de synchronisation n’est nécessaire ; le dataflow lui-même impose l’ordre.
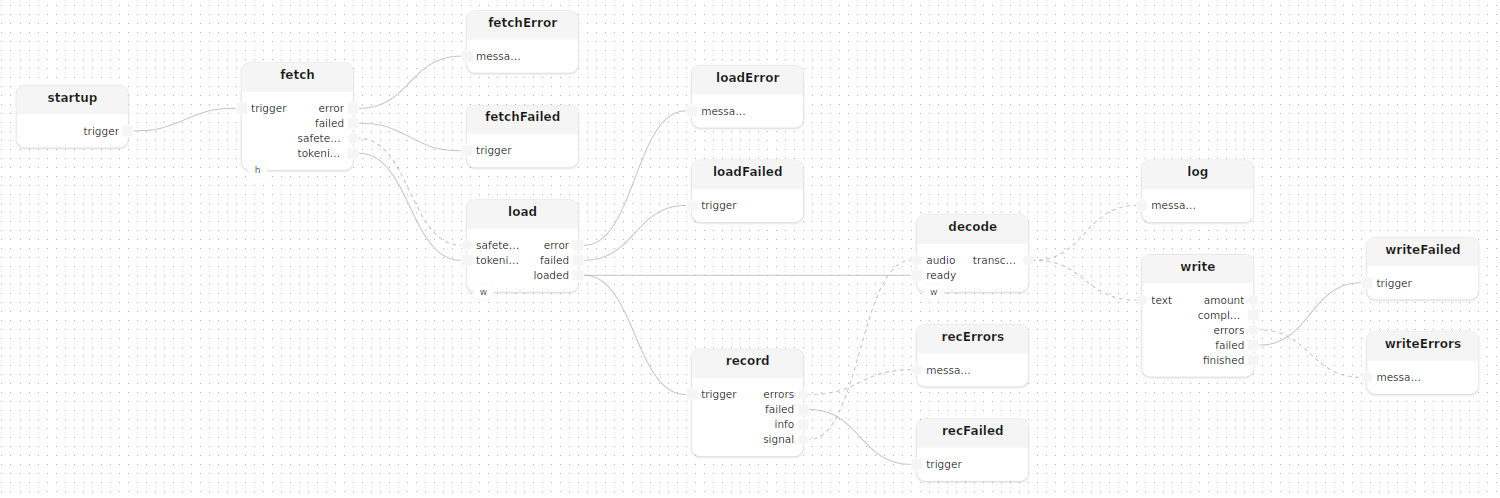
Fan-out vers le journal et le fichier
Une fois qu’un segment est transcrit par Whisper, il est transmis à deux sorties simultanément grâce à la double flèche --> :
decode.transcribed --> log.messages
decode.transcribed --> write.text
}Les deux opérations s’exécutent en parallèle.
Point d’entrée fromfile
Le point d’entrée fromFile remplace recordMono par readLocal et decodeMono :
treatment fromFile(
const input_file: string,
const output: string = "transcription.txt"
)
model hub: Hub()
model whisper: Speech()
{
startup()
fetch[hub=hub]()
load[whisper=whisper]()
decode[whisper=whisper]()
read: readLocal(path=input_file)
audioDecode: decodeMono(hint="wav")
log: logInfos(label="transcription")
write: writeTextLocal(path=output, append=false)
startup.trigger -> fetch.trigger
fetch.safetensors -> load.safetensors
fetch.tokenizer -> load.tokenizer
load.loaded -> decode.ready
load.loaded -> read.trigger
read.data -> audioDecode.data
audioDecode.signal -> decode.audio
decode.transcribed --> log.messages
decode.transcribed --> write.text
}Le traitement decodeMono(hint="wav") gère la détection du format de conteneur de manière transparente ; le même pipeline fonctionne pour WAV, MP3, FLAC et d’autres formats.
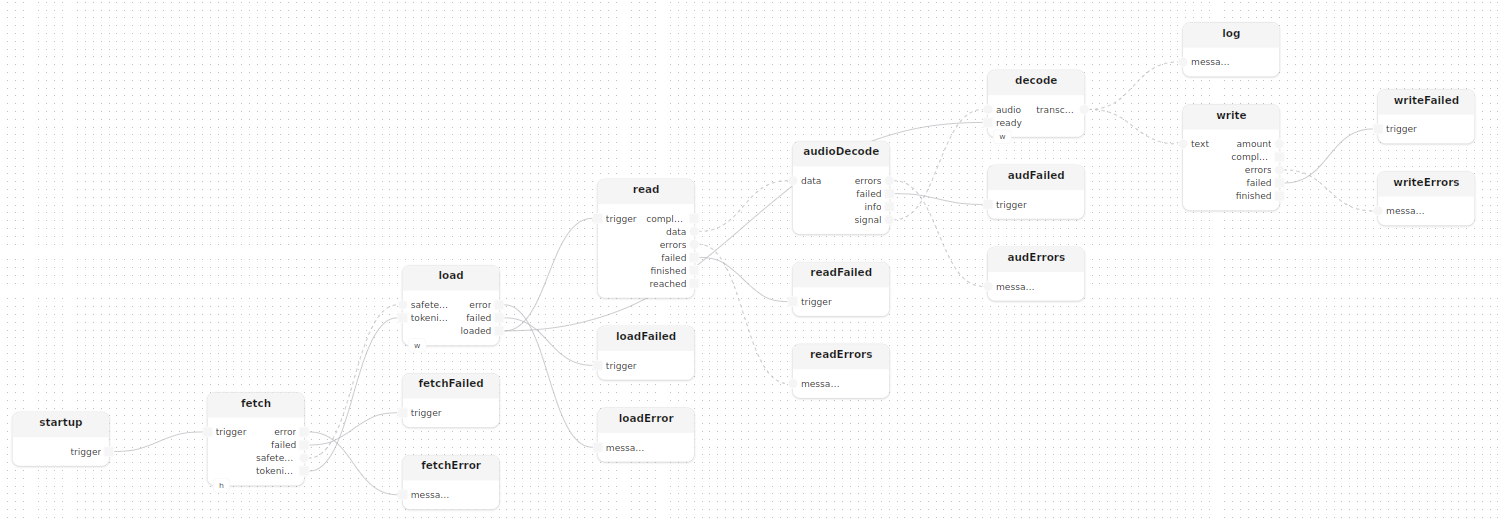
Dépendances
[dependencies]
std = "0.10.1" # flux de base, journalisation, structures de données
fs = "0.10.1" # lecture/écriture de fichiers locaux
audio = "0.10.1" # décodage / encodage / rééchantillonnage audio
record = "0.10.1" # capture microphone
ml = "0.10.1" # inférence LLM, STT, TTS et modèles locaux