Q&A vocal (local)
Un pipeline de Q&A vocal entièrement hors ligne : microphone → Whisper local (parole-vers-texte) → Mistral 7B local (génération de texte) → journal et fichier de sortie. Aucune clé d’API n’est requise après le téléchargement initial des modèles depuis HuggingFace.
Exécution
melodium run 07_voice_qa_local/Compo.toml --output qa.txt[…] info: pipeline: both models ready, listening…
[…] info: answer: Mélodium est un langage de programmation dataflow conçu pour …Nécessite environ 14 Go de RAM pour Mistral 7B.
Fonctionnement
Quatre modèles sont déclarés : deux pointeurs HfHub (un par dépôt de modèle) et deux modèles d’inférence :
model WhisperHub() : HfHub { repo_id = "openai/whisper-tiny" }
model MistralHub() : HfHub { repo_id = "mistralai/Mistral-7B-v0.1" }
model Asr() : Whisper {}
model Llm() : Mistral { temperature = 0.7, top_p = 0.9, max_new_tokens = 256 }Chargement parallèle des modèles
Les deux modèles sont téléchargés en parallèle dès que startup se déclenche :
treatment main(const output: string = "qa.txt")
model whisperHub: WhisperHub()
model mistralHub: MistralHub()
model asr: Asr()
model llm: Llm()
{
startup()
fetchAsr: fetch[hub=whisperHub]()
fetchLlm: fetch[hub=mistralHub]()
loadAsr: loadWhisper[whisper=asr]()
loadLlm: loadMistral[mistral=llm]()
startup.trigger -> fetchAsr.trigger
startup.trigger -> fetchLlm.trigger
fetchAsr.safetensors -> loadAsr.safetensors
fetchAsr.tokenizer -> loadAsr.tokenizer
fetchLlm.safetensors -> loadLlm.safetensors
fetchLlm.tokenizer -> loadLlm.tokenizer
logReady: logInfoMessage(label="pipeline", message="both models ready — listening…")
loadLlm.loaded -> logReady.trigger
asrDecode: decode[whisper=asr]()
record: recordMono(device=_, sample_rate=_)
loadAsr.loaded -> record.trigger
loadAsr.loaded -> asrDecode.ready
record.signal -> asrDecode.audio
promptLlm[llm=llm]()
asrDecode.transcribed -> promptLlm.question
logAnswer: logInfos(label="answer")
write: writeTextLocal(path=output, append=true)
promptLlm.answer --> logAnswer.messages
promptLlm.answer --> write.text
}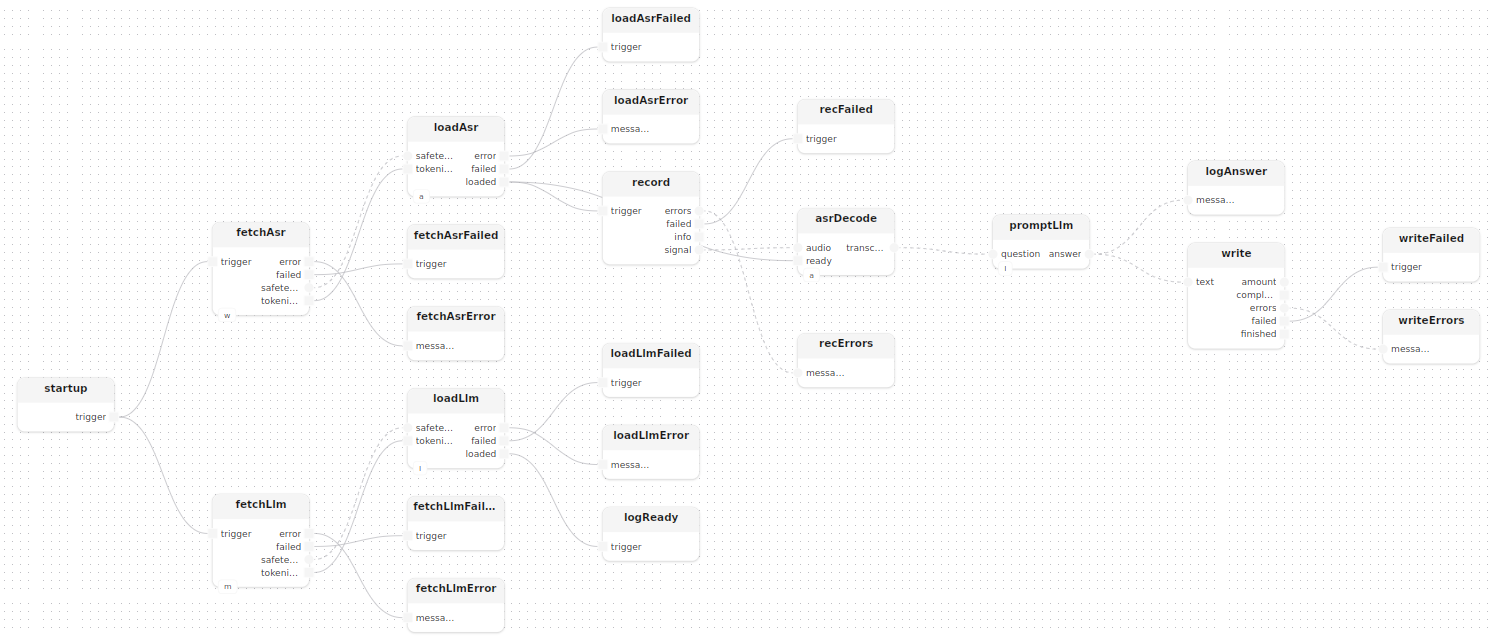
La capture audio démarre dès que le modèle ASR est chargé (loadAsr.loaded). Le LLM peut finir de se charger en parallèle ; s’il n’est pas prêt au moment où la première transcription arrive, le dataflow bloque naturellement jusqu’à ce qu’il le soit.
Formatage du prompt
Chaque segment transcrit est formaté dans le template de prompt [INST] de Mistral avant d’être envoyé au modèle :
treatment promptLlm[llm: Mistral]()
input question: Stream<string>
output answer: Stream<string>
{
wrapEntry: entry(key="q")
fmt: format(format="[INST] {q} [/INST]")
generate[mistral=llm]()
Self.question -> wrapEntry.value,map -> fmt.entries,formatted -> generate.prompt,generated -> Self.answer
}entry(key="q") enveloppe la chaîne dans une StringMap, et format(format="[INST] {q} [/INST]") l’interpole. Cela évite la concaténation de chaînes et garde le template lisible.
Dépendances
[dependencies]
std = "0.10.1" # flux de base, journalisation, structures de données
fs = "0.10.1" # lecture/écriture de fichiers locaux
audio = "0.10.1" # décodage / encodage / rééchantillonnage audio
record = "0.10.1" # capture microphone
ml = "0.10.1" # inférence LLM, STT, TTS et modèles locaux