Inférence LLM distribuée
Source: 15_distributed_llm_inference
Un serveur HTTP qui accepte des prompts en texte brut et renvoie les réponses LLM en flux. L’appel LLM s’exécute sur un runner Mélodium cloud ; le package ml n’a besoin d’être disponible que sur le runner, pas sur la machine locale. Celle-ci ne requiert aucune dépendance ML.
Exécution
melodium run 15_distributed_llm_inference/Compo.toml \
--api_token "my-api-token" \
--openai_key sk-... \
--port 8080api_token authentifie ici auprès d’une API Mélodium Services, comme Cadence.CI . openai_key est une clé d’API OpenAI , transmise au runner distant.
$ curl -X POST http://127.0.0.1:8080/chat \
-H "Content-Type: text/plain" \
-d "Explain the Mélodium dataflow model in one sentence."
Mélodium is a dataflow programming language…Fonctionnement
server instancie les modèles DistantEngine, DistributionEngine et le HttpServer local. Le modèle Assistant (une enveloppe LLM) est défini ici mais n’est instancié que sur le runner distant :
model Assistant(const openai_key: string) : RemoteLlm {
backend = "openai"
api_key = |wrap<string>(openai_key)
base_url = ""
model = "gpt-4o-mini"
system = "You are a concise and helpful assistant."
max_tokens = |wrap<u64>(1024)
temperature = _
top_p = _
timeout = _
}
model runner: DistantEngine(api_url=|wrap<string>("https://api.melodium.tech/0.1"), api_token=|wrap<string>(api_token))
model distributor: DistributionEngine(
treatment = "distributed_llm_inference/main::inferText",
version = "0.1.0"
)
model httpServer: HttpServer(host=|from_ipv4(|localhost_ipv4()), port=port)La machine locale n’a besoin que des packages http, distrib et work ; le package ml (et sa logique d’appel API) réside entièrement sur le runner.
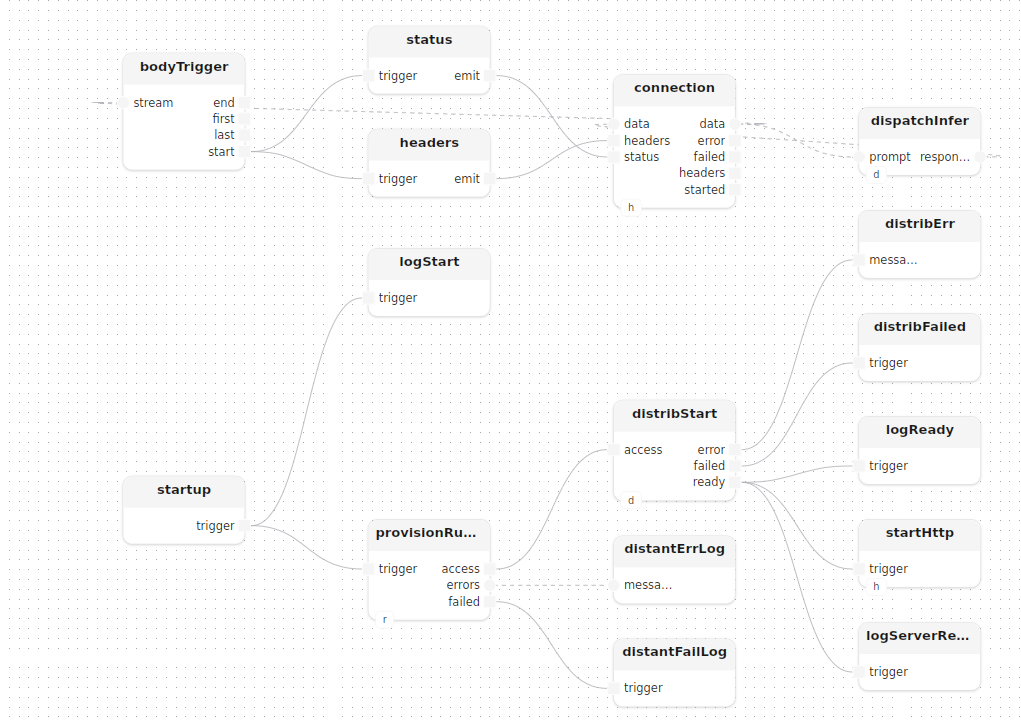
Passer des paramètres const au traitement distant
inferText a besoin de openai_key pour configurer son modèle Assistant, mais les paramètres const ne peuvent pas être passés via des flux. Ils sont envoyés via l’appel start du moteur de distribution, une seule fois, au moment de la connexion :
provisionRunner: distant[distant_engine=runner](
max_duration = 600,
memory = 512, // Mo
cpu = 1000, // millicœurs
storage = 512, // Mo
edition = _,
arch = _,
volumes = [],
containers = [],
service_containers = [],
tags = []
)
startup.trigger -> provisionRunner.trigger,access -> distribStart.access
distribStart: start[distributor=distributor](params=|map([|entry<string>("openai_key", openai_key)]))Côté distant, inferText déclare le même paramètre en const :
treatment inferText(const openai_key: string)
model llm: Assistant(openai_key=openai_key)
input prompt: Stream<byte>
output response: Stream<byte>Un paramètre var exigerait au contraire des données propres à chaque invocation, ce à quoi servent sendStream / recvStream.
Ce n’est qu’une fois distribStart.ready déclenché que startHttp et le message de log de disponibilité s’exécutent, de sorte qu’aucune requête ne peut arriver avant que le worker distant ne soit connecté :
startHttp[http_server=httpServer]()
distribStart.ready -> startHttp.triggerDistribution de chaque requête
dispatchInfer encapsule distribute, sendStream et recvStream :
treatment dispatchInfer[distributor: DistributionEngine]()
input prompt: Stream<byte>
output response: Stream<byte>
{
trig: trigger<byte>()
dist: distribute[distributor=distributor]()
Self.prompt -> trig.stream,start -> dist.trigger
sendPrompt: sendStream<byte>[distributor=distributor](name="prompt")
recvResponse: recvStream<byte>[distributor=distributor](name="response")
dist.distribution_id -> sendPrompt.distribution_id
dist.distribution_id -> recvResponse.distribution_id
Self.prompt -> sendPrompt.data
recvResponse.data -> Self.response
}
connection.data -> dispatchInfer.prompt,response -> connection.dataLes noms de flux ("prompt", "response") correspondent aux noms de ports de inferText.
Le traitement distant inferText
treatment inferText(const openai_key: string)
model llm: Assistant(openai_key=openai_key)
input prompt: Stream<byte>
output response: Stream<byte>
{
decodePrompt: decode()
Self.prompt -> decodePrompt.data,text -> doChat.prompt
doChat: chat[llm=llm]()
chatErrLog: logErrors(label="llm")
doChat.error -> chatErrLog.messages
encodeResponse: encode()
doChat.response -> encodeResponse.text,data -> Self.response
}decode convertit les octets du prompt en chaîne UTF-8, chat appelle le LLM (GPT-4o-mini via OpenAI) et émet les tokens de réponse sous forme de Stream<string>, et encode reconvertit chaque token en octets avant qu’il ne rejoigne Self.response. Comme doChat.response émet token par token, recvResponse.data est transmis directement dans connection.data : le client HTTP voit les tokens apparaître au fur et à mesure de leur génération, sans tampon intermédiaire.

Dépendances
[dependencies]
std = "0.10.1" # flux de base, journalisation, structures de données
http = "0.10.1" # serveur et client HTTP
net = "0.10.1" # utilitaires d'adresses IP
encoding = "0.10.1" # encodage / décodage UTF-8
work = "0.10.1" # provisionnement de runners cloud
distrib = "0.10.1" # distribution de flux entre runners
ml = "0.10.1" # inférence LLM, STT, TTS et modèles locaux