Pipeline vocal complet
Source: 08_full_voice_pipeline
Une boucle parole-entrée / parole-sortie complète utilisant trois APIs cloud : lit un fichier audio, le transcrit avec OpenAI Whisper, génère une réponse avec GPT-4o, synthétise la réponse en parole avec ElevenLabs, et écrit le fichier audio de sortie.
Exécution
melodium run 08_full_voice_pipeline/Compo.toml \
--input_file question.wav \
--openai_key sk-... \
--elevenlabs_key el-... \
--elevenlabs_voice JBFqnCBsd6RMkjVDRZzbopenai_key est une clé d’API OpenAI . elevenlabs_key est une clé d’API ElevenLabs .
[…] info: pipeline: starting voice pipeline…
[…] info: pipeline: answer writtenFonctionnement
Trois modèles couvrent les trois étapes d’API, chacun une fine enveloppe autour d’un modèle ML distant avec une configuration fixe :
model Stt(const openai_key: string) : RemoteStt {
backend = "openai"
api_key = |wrap<string>(openai_key)
base_url = ""
model = "whisper-1"
}
model Llm(const openai_key: string) : RemoteLlm {
backend = "openai"
api_key = |wrap<string>(openai_key)
base_url = ""
model = "gpt-4o"
system = "You are a helpful voice assistant. Answer briefly and clearly."
max_tokens = |wrap<u64>(256)
temperature = |wrap<f32>(0.7)
top_p = _
timeout = _
}
model Tts(const elevenlabs_key: string, const voice: string) : RemoteTts {
backend = "elevenlabs"
api_key = |wrap<string>(elevenlabs_key)
base_url = ""
model = "eleven_multilingual_v2"
voice = voice
}Le traitement startup instancie les trois modèles et connecte le pipeline comme une séquence directe de sous-traitements :
model stt: Stt(openai_key=openai_key)
model llm: Llm(openai_key=openai_key)
model tts: Tts(elevenlabs_key=elevenlabs_key, voice=elevenlabs_voice)
read: readLocal(path=input_file)
startup.trigger -> read.trigger
sttTranscribe[stt=stt]()
read.data -> sttTranscribe.audio
llmRespond[llm=llm]()
sttTranscribe.transcript -> llmRespond.question
ttsSpeak[tts=tts]()
llmRespond.answer -> ttsSpeak.text
write: writeLocal(path=output_file)
ttsSpeak.audio -> write.data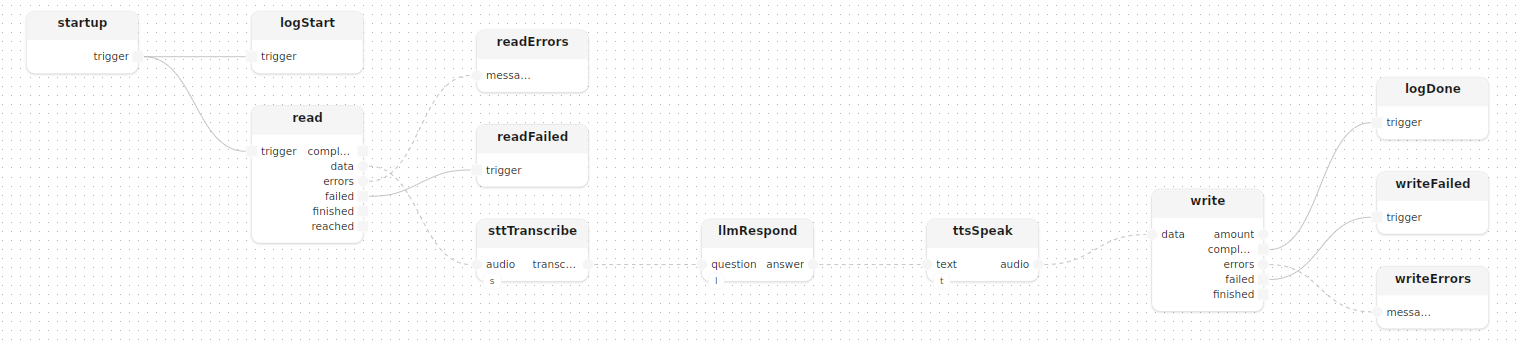
Frontière Block/Stream à la sortie STT
sttTranscribe[stt] envoie l’ensemble du flux d’octets audio à transcribe (STT distant), qui retourne un Block<string>, une seule valeur pour tout le fichier audio. Le traitement llmRespond en aval attend une entrée Stream<string>, donc stream<string>() fait le pont entre les deux :
treatment sttTranscribe[stt: RemoteStt]()
input audio: Stream<byte>
output transcript: Stream<string>
{
transcribe[stt=stt]()
transcriptAsStream: stream<string>()
Self.audio -> transcribe.audio
transcribe.transcript -> transcriptAsStream.block,stream -> Self.transcript
}Construction du prompt et réponse en flux
llmRespond[llm] enveloppe chaque chaîne de transcription dans un modèle de prompt via entry et format, puis appelle chat de RemoteLlm, qui renvoie les tokens de la réponse en flux au fur et à mesure de leur arrivée :
treatment llmRespond[llm: RemoteLlm]()
input question: Stream<string>
output answer: Stream<string>
{
wrapEntry: entry(key="q")
fmt: format(format="User asked: {q}\nPlease answer helpfully.")
chat[llm=llm]()
Self.question -> wrapEntry.value,map -> fmt.entries,formatted -> chat.prompt,response -> Self.answer
}Sortie TTS
ttsSpeak[tts] envoie chaque chaîne de réponse directement à synthesize de RemoteTts, qui émet les octets audio sous forme de Stream<byte> écrits par writeLocal :
treatment ttsSpeak[tts: RemoteTts]()
input text: Stream<string>
output audio: Stream<byte>
{
synthesize[tts=tts]()
Self.text -> synthesize.text,audio -> Self.audio
}Le flux de sortie est écrit directement dans le fichier de sortie. Le format audio (MP3 par défaut pour ElevenLabs) est déterminé par le backend TTS. Chacun des trois sous-traitements garde une signature claire Stream<T> en entrée / Stream<T> en sortie et gère son propre journal d’erreurs, ce qui rend chaque étape indépendamment remplaçable.
Dépendances
[dependencies]
std = "0.10.1" # flux de base, journalisation, structures de données
fs = "0.10.1" # lecture/écriture de fichiers locaux
audio = "0.10.1" # décodage / encodage / rééchantillonnage audio
record = "0.10.1" # capture microphone
ml = "0.10.1" # inférence LLM, STT, TTS et modèles locaux