Résumé de réunion
Source: 10_meeting_summary_service
Un serveur HTTP qui accepte des envois audio bruts, les transcrit avec l’API ElevenLabs Scribe, génère un résumé structuré de réunion avec Claude Sonnet, et renvoie le résumé en flux dans la réponse HTTP. Chaque requête est traitée dans sa propre track ; le serveur gère plusieurs envois simultanés sans aucune gestion explicite de fils d’exécution.
Exécution
melodium run 10_meeting_summary_service/Compo.toml \
--anthropic_key sk-ant-... \
--elevenlabs_key el-...anthropic_key est une clé d’API Anthropic . elevenlabs_key est une clé d’API ElevenLabs .
$ curl -X POST http://127.0.0.1:8080/summarise \
--data-binary @meeting.wav \
-H "Content-Type: audio/wav"
## Résumé de réunion
**Vue d'ensemble :** …
**Décisions clés :**
- …
**Actions :**
- …Fonctionnement
Deux modèles enveloppent les backends STT et LLM distants :
model Stt(const elevenlabs_key: string) : RemoteStt {
backend = "elevenlabs"
api_key = |wrap<string>(elevenlabs_key)
base_url = ""
model = "scribe_v1"
}
model Llm(const anthropic_key: string) : RemoteLlm {
backend = "anthropic"
api_key = |wrap<string>(anthropic_key)
base_url = ""
model = "claude-sonnet-4-6"
system = "You are an expert meeting assistant. Given a raw transcript, produce a concise, structured summary with: key decisions, action items, and a one-paragraph overview."
max_tokens = 512
temperature = 0.4
top_p = _
timeout = _
}Stt utilise le modèle ElevenLabs scribe_v1. Llm utilise Claude Sonnet avec un system prompt de résumé structuré et une température plus basse (0,4) pour produire une sortie concentrée et cohérente. Les trois modèles, y compris le HttpServer, sont instanciés au démarrage :
treatment main(
const anthropic_key: string,
const elevenlabs_key: string,
const port: u16 = 8080
)
model server: HttpServer(host=|from_ipv4(|localhost_ipv4()), port=port)
model stt: Stt(elevenlabs_key=elevenlabs_key)
model llm: Llm(anthropic_key=anthropic_key)
{
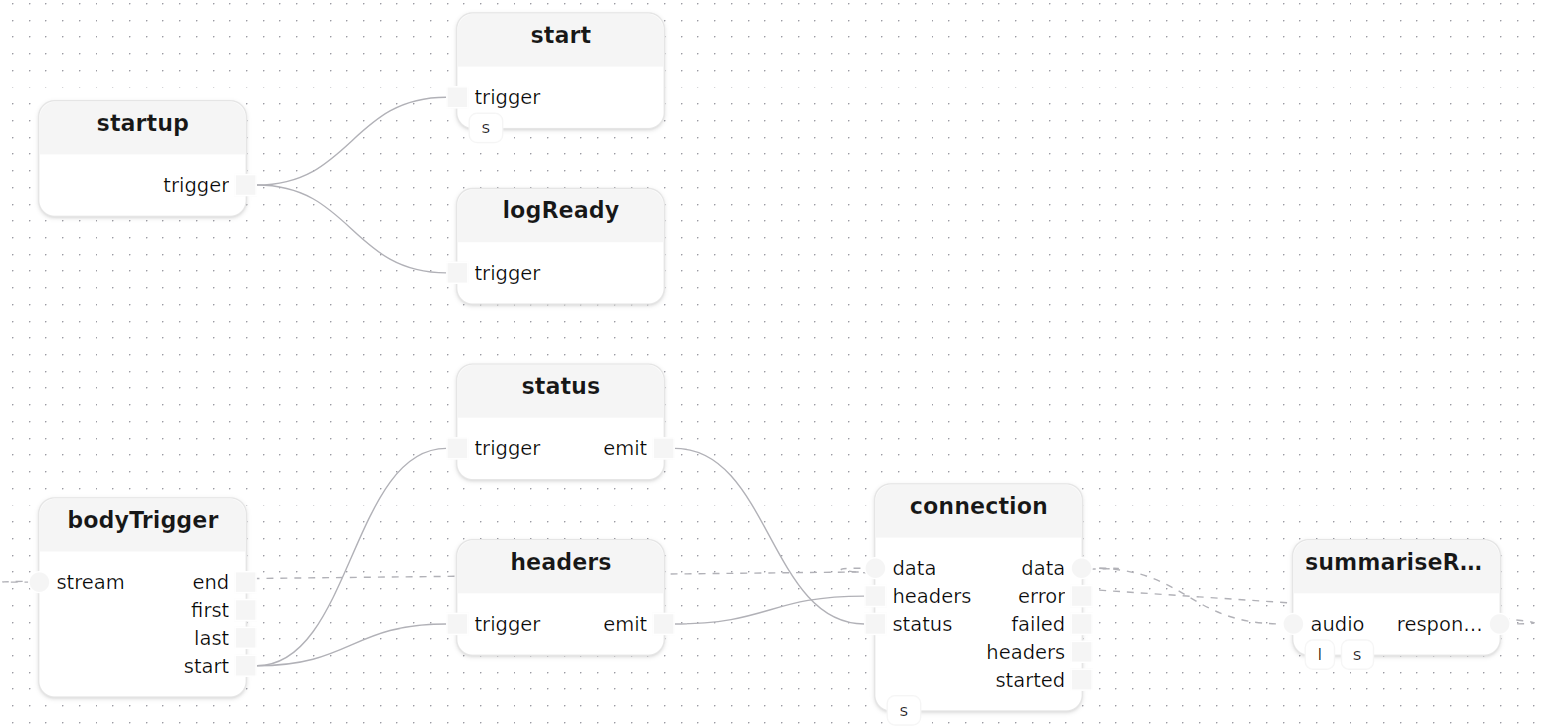
startup()
start[http_server=server]()
logReady: logInfoMessage(label="service", message="meeting summary service ready")
startup.trigger -> start.trigger
startup.trigger -> logReady.trigger
connection[http_server=server](method=|post(), route="/summarise")
status: emit<HttpStatus>(value=|ok())
headers: emit<StringMap>(value=|map([]))
bodyTrigger: trigger<byte>()
connection.data -> bodyTrigger.stream,start --> status.trigger,emit -> connection.status
bodyTrigger.start --------> headers.trigger,emit -> connection.headers
summariseRequest[stt=stt, llm=llm]()
connection.data -> summariseRequest.audio,response -> connection.data
}
Pipeline par requête
Le sous-traitement summariseRequest gère tout pour une requête :
treatment summariseRequest[stt: RemoteStt, llm: RemoteLlm]()
input audio: Stream<byte>
output response: Stream<byte>
{
transcribe[stt=stt]()
transcriptStream: stream<string>()
sttFailed: logErrorMessage(label="stt", message="transcription failed")
sttError: logError(label="stt")
Self.audio -> transcribe.audio
transcribe.transcript -> transcriptStream.block,stream -> buildSummaryPrompt.transcript
transcribe.failed -> sttFailed.trigger
transcribe.error -> sttError.message
buildSummaryPrompt()
chat[llm=llm]()
encode()
llmErrors: logErrors(label="llm")
buildSummaryPrompt.prompt -> chat.prompt,response -> encode.text,data -> Self.response
chat.error -> llmErrors.messages
}transcribe retourne un Block<string>. L’adaptateur stream<string>() le convertit en Stream<string> pour qu’il puisse s’écouler dans buildSummaryPrompt, qui enveloppe la transcription brute dans un template de prompt via entry et format :
treatment buildSummaryPrompt()
input transcript: Stream<string>
output prompt: Stream<string>
{
wrapEntry: entry(key="t")
fmt: format(format="Here is the meeting transcript:\n\n{t}\n\nPlease produce a structured meeting summary.")
Self.transcript -> wrapEntry.value,map -> fmt.entries,formatted -> Self.prompt
}chat de RemoteLlm retourne un Stream<string> de tokens de réponse, encodés et transmis directement dans connection.data. Les tokens du résumé apparaissent dans la réponse HTTP au fur et à mesure de leur génération.

Explication vidéo
Dépendances
[dependencies]
std = "0.10.1" # flux de base, journalisation, structures de données
http = "0.10.1" # serveur et client HTTP
net = "0.10.1" # utilitaires d'adresses IP
encoding = "0.10.1" # encodage / décodage UTF-8
ml = "0.10.1" # inférence LLM, STT, TTS et modèles locaux