Batch Transcription
Source: 09_batch_transcription
Reads a local audio file, uploads it to the OpenAI Whisper API in one shot, and writes the transcript to a text file. Unlike the local speech transcription example, no model needs to be downloaded; the full audio is sent and a single transcript block is received back.
Running
melodium run 09_batch_transcription/Compo.toml \
--input meeting.wav \
--openai_key sk-...Note
openai_key is an OpenAI API key.
[…] info: stt: reading audio file…
[…] info: stt: transcription completeHow it works
Stt wraps RemoteStt with a fixed backend and model:
model Stt(const openai_key: string) : RemoteStt {
backend = "openai"
api_key = |wrap<string>(openai_key)
base_url = ""
model = "whisper-1"
}startup fires readLocal, whose output feeds directly into transcribe:
treatment main(
const input: string,
const output: string = "transcript.txt",
const openai_key: string
)
model stt: Stt(openai_key=openai_key)
{
startup()
logStart: logInfoMessage(label="stt", message="reading audio file…")
startup.trigger -> logStart.trigger
read: readLocal(path=input)
startup.trigger -> read.trigger
readFailed: logErrorMessage(label="read", message="audio file could not be read")
readErrors: logErrors(label="read")
read.failed -> readFailed.trigger
read.errors -> readErrors.messages
transcribe[stt=stt]()
read.data -> transcribe.audio
sttFailed: logErrorMessage(label="stt", message="transcription failed")
sttError: logError(label="stt")
transcribe.failed -> sttFailed.trigger
transcribe.error -> sttError.message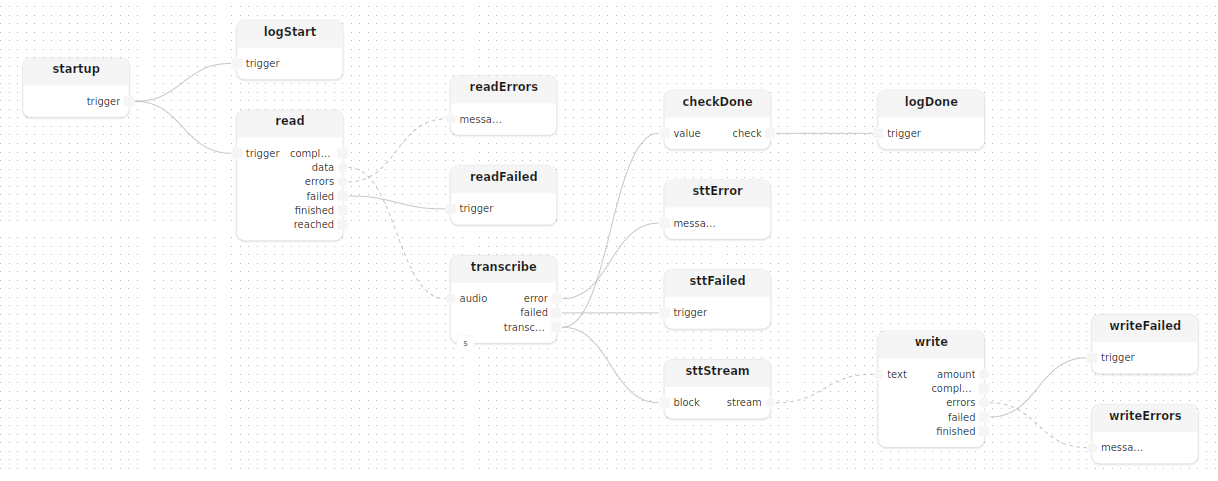
Block/Stream bridging
transcribe.transcript is a Block<string>, a single value emitted once the full transcript is ready. Two downstream operations consume it, requiring two different adapters:
logDone: logInfoMessage(label="stt", message="transcription complete")
checkDone: check<string>()
sttStream: stream<string>()
write: writeTextLocal(path=output)
transcribe.transcript --> checkDone.value,check -> logDone.trigger
transcribe.transcript --> sttStream.block,stream -> write.text
writeFailed: logErrorMessage(label="write", message="output write failed")
writeErrors: logErrors(label="write")
write.failed -> writeFailed.trigger
write.errors -> writeErrors.messages
}check<string>()discards the string value and emitsBlock<void>, used only to trigger the logstream<string>()converts theBlock<string>into aStream<string>thatwriteTextLocalcan consume
The --> fan-out feeds both branches simultaneously from the single transcript block.
Dependencies
[dependencies]
std = "0.10.1" # core flows, logging, data structures
fs = "0.10.1" # local file I/O
ml = "0.10.1" # LLM, STT, TTS and local model inference