Distributed LLM Inference
Source: 15_distributed_llm_inference
An HTTP server that accepts plain-text prompts and streams LLM responses back. The LLM call runs on a Mélodium cloud runner; the ml package only needs to be available on the runner, not on the front-end machine. The front-end requires no ML dependencies at all.
Running
melodium run 15_distributed_llm_inference/Compo.toml \
--api_token "my-api-token" \
--openai_key sk-... \
--port 8080api_token here authenticates against a Mélodium Services API, such as Cadence.CI . openai_key is an OpenAI API key, forwarded to the remote runner.
$ curl -X POST http://127.0.0.1:8080/chat \
-H "Content-Type: text/plain" \
-d "Explain the Mélodium dataflow model in one sentence."
Mélodium is a dataflow programming language…How it works
server instantiates the DistantEngine, DistributionEngine, and local HttpServer models. The Assistant model (an LLM wrapper) is defined here but only instantiated on the remote runner:
model Assistant(const openai_key: string) : RemoteLlm {
backend = "openai"
api_key = |wrap<string>(openai_key)
base_url = ""
model = "gpt-4o-mini"
system = "You are a concise and helpful assistant."
max_tokens = |wrap<u64>(1024)
temperature = _
top_p = _
timeout = _
}
model runner: DistantEngine(api_url=|wrap<string>("https://api.melodium.tech/0.1"), api_token=|wrap<string>(api_token))
model distributor: DistributionEngine(
treatment = "distributed_llm_inference/main::inferText",
version = "0.1.0"
)
model httpServer: HttpServer(host=|from_ipv4(|localhost_ipv4()), port=port)The front-end only needs the http, distrib, and work packages; the ml package (and its API call logic) lives entirely on the runner.
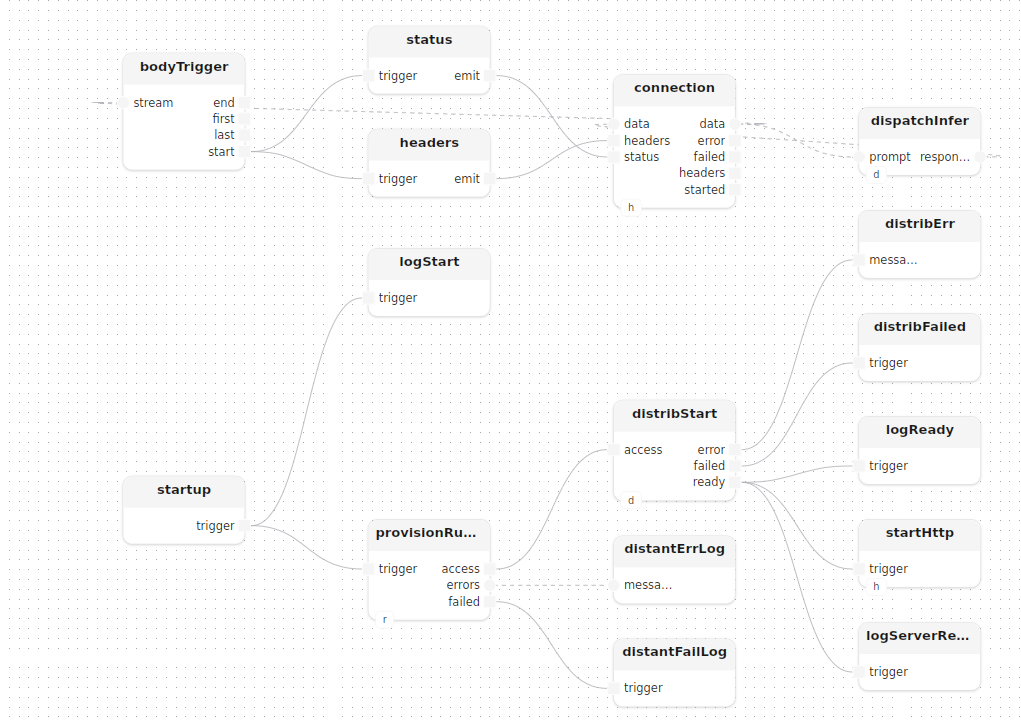
Passing const parameters to the remote treatment
inferText needs openai_key to configure its Assistant model, but const parameters cannot be passed through streams. They are sent via the distribution engine’s start call, once, at connection time:
provisionRunner: distant[distant_engine=runner](
max_duration = 600,
memory = 512, // MB
cpu = 1000, // millicores
storage = 512, // MB
edition = _,
arch = _,
volumes = [],
containers = [],
service_containers = [],
tags = []
)
startup.trigger -> provisionRunner.trigger,access -> distribStart.access
distribStart: start[distributor=distributor](params=|map([|entry<string>("openai_key", openai_key)]))On the remote side, inferText declares the same parameter as const:
treatment inferText(const openai_key: string)
model llm: Assistant(openai_key=openai_key)
input prompt: Stream<byte>
output response: Stream<byte>A var parameter would instead require per-invocation data, which is what sendStream / recvStream are for.
Only after distribStart.ready fires do both startHttp and the ready log run, so no request can arrive before the remote worker is connected:
startHttp[http_server=httpServer]()
distribStart.ready -> startHttp.triggerDispatching each request
dispatchInfer wraps distribute, sendStream, and recvStream:
treatment dispatchInfer[distributor: DistributionEngine]()
input prompt: Stream<byte>
output response: Stream<byte>
{
trig: trigger<byte>()
dist: distribute[distributor=distributor]()
Self.prompt -> trig.stream,start -> dist.trigger
sendPrompt: sendStream<byte>[distributor=distributor](name="prompt")
recvResponse: recvStream<byte>[distributor=distributor](name="response")
dist.distribution_id -> sendPrompt.distribution_id
dist.distribution_id -> recvResponse.distribution_id
Self.prompt -> sendPrompt.data
recvResponse.data -> Self.response
}
connection.data -> dispatchInfer.prompt,response -> connection.dataThe stream names ("prompt", "response") match inferText’s own port names.
The remote inferText treatment
treatment inferText(const openai_key: string)
model llm: Assistant(openai_key=openai_key)
input prompt: Stream<byte>
output response: Stream<byte>
{
decodePrompt: decode()
Self.prompt -> decodePrompt.data,text -> doChat.prompt
doChat: chat[llm=llm]()
chatErrLog: logErrors(label="llm")
doChat.error -> chatErrLog.messages
encodeResponse: encode()
doChat.response -> encodeResponse.text,data -> Self.response
}decode converts the prompt bytes to a UTF-8 string, chat calls the LLM (GPT-4o-mini via OpenAI) and emits response tokens as Stream<string>, and encode converts each token back to bytes before it flows to Self.response. Because doChat.response streams token by token, recvResponse.data forwards directly into connection.data: the HTTP client sees tokens appear as they are generated, with no intermediate buffering.

Dependencies
[dependencies]
std = "0.10.1" # core flows, logging, data structures
http = "0.10.1" # HTTP server and client
net = "0.10.1" # IP address helpers
encoding = "0.10.1" # UTF-8 encode / decode
work = "0.10.1" # cloud runner provisioning
distrib = "0.10.1" # stream distribution across runners
ml = "0.10.1" # LLM, STT, TTS and local model inference