Voice Q&A (Local)
A fully offline voice Q&A pipeline: microphone → local Whisper (speech-to-text) → local Mistral 7B (text generation) → log and file output. No API keys are required after the initial model download from HuggingFace.
Running
melodium run 07_voice_qa_local/Compo.toml --output qa.txt[…] info: pipeline: both models ready, listening…
[…] info: answer: Mélodium is a dataflow programming language designed for …Requires approximately 14 GB of RAM for Mistral 7B.
How it works
Four models are declared: two HfHub pointers (one per model repository) and two inference models:
model WhisperHub() : HfHub { repo_id = "openai/whisper-tiny" }
model MistralHub() : HfHub { repo_id = "mistralai/Mistral-7B-v0.1" }
model Asr() : Whisper {}
model Llm() : Mistral { temperature = 0.7, top_p = 0.9, max_new_tokens = 256 }Parallel model loading
Both models are fetched concurrently from the moment startup fires:
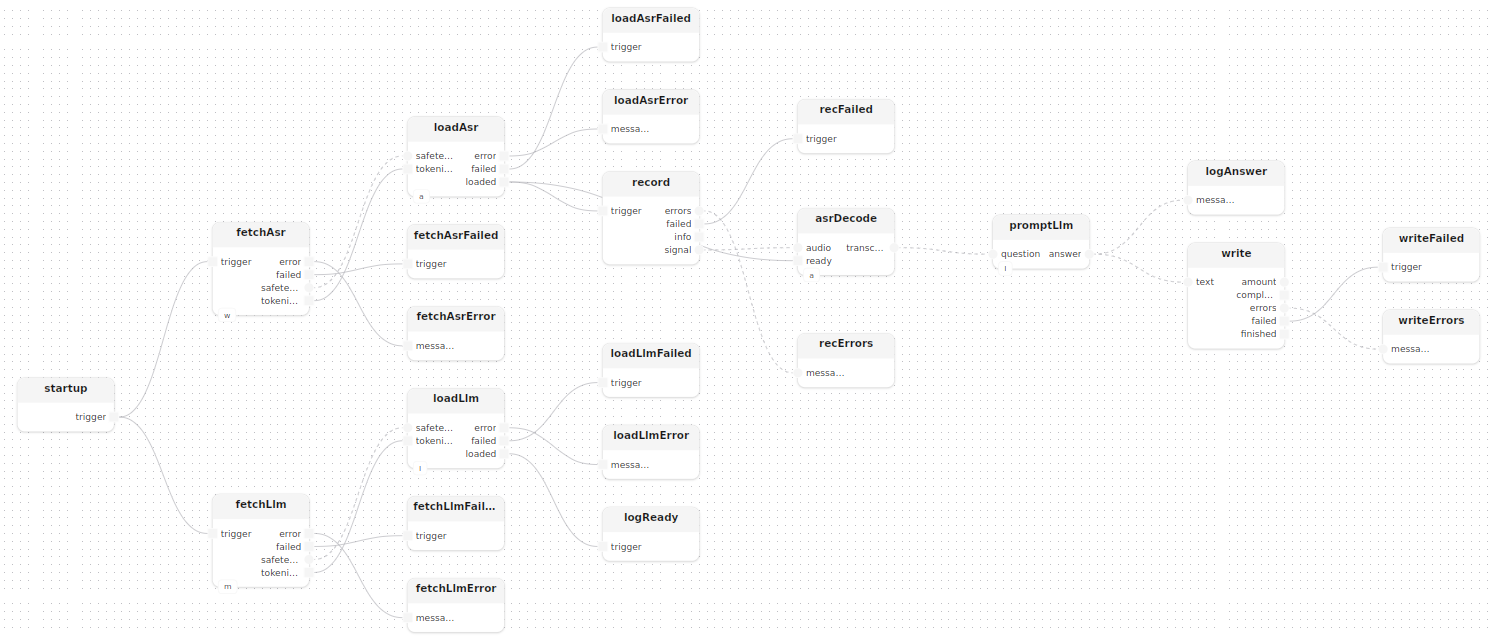
treatment main(const output: string = "qa.txt")
model whisperHub: WhisperHub()
model mistralHub: MistralHub()
model asr: Asr()
model llm: Llm()
{
startup()
fetchAsr: fetch[hub=whisperHub]()
fetchLlm: fetch[hub=mistralHub]()
loadAsr: loadWhisper[whisper=asr]()
loadLlm: loadMistral[mistral=llm]()
startup.trigger -> fetchAsr.trigger
startup.trigger -> fetchLlm.trigger
fetchAsr.safetensors -> loadAsr.safetensors
fetchAsr.tokenizer -> loadAsr.tokenizer
fetchLlm.safetensors -> loadLlm.safetensors
fetchLlm.tokenizer -> loadLlm.tokenizer
logReady: logInfoMessage(label="pipeline", message="both models ready — listening…")
loadLlm.loaded -> logReady.trigger
asrDecode: decode[whisper=asr]()
record: recordMono(device=_, sample_rate=_)
loadAsr.loaded -> record.trigger
loadAsr.loaded -> asrDecode.ready
record.signal -> asrDecode.audio
promptLlm[llm=llm]()
asrDecode.transcribed -> promptLlm.question
logAnswer: logInfos(label="answer")
write: writeTextLocal(path=output, append=true)
promptLlm.answer --> logAnswer.messages
promptLlm.answer --> write.text
}
Audio capture starts as soon as the ASR model is loaded (loadAsr.loaded). The LLM can finish loading in parallel; if it is not ready by the time the first transcription arrives, the dataflow naturally blocks until it is.
Prompt formatting
Each transcribed segment is formatted into the Mistral [INST] prompt template before being sent to the model:
treatment promptLlm[llm: Mistral]()
input question: Stream<string>
output answer: Stream<string>
{
wrapEntry: entry(key="q")
fmt: format(format="[INST] {q} [/INST]")
generate[mistral=llm]()
Self.question -> wrapEntry.value,map -> fmt.entries,formatted -> generate.prompt,generated -> Self.answer
}entry(key="q") wraps the string into a StringMap, and format(format="[INST] {q} [/INST]") interpolates it. This avoids string concatenation and keeps the template readable.
Dependencies
[dependencies]
std = "0.10.1" # core flows, logging, data structures
fs = "0.10.1" # local file I/O
audio = "0.10.1" # audio decode / encode / resample
record = "0.10.1" # microphone capture
ml = "0.10.1" # LLM, STT, TTS and local model inference