Full Voice Pipeline
Source: 08_full_voice_pipeline
A complete speech-in / speech-out loop using three cloud APIs: reads an audio file, transcribes it with OpenAI Whisper, generates a response with GPT-4o, synthesises the response as speech with ElevenLabs, and writes the output audio file.
Running
melodium run 08_full_voice_pipeline/Compo.toml \
--input_file question.wav \
--openai_key sk-... \
--elevenlabs_key el-... \
--elevenlabs_voice JBFqnCBsd6RMkjVDRZzbopenai_key is an OpenAI API key. elevenlabs_key is an ElevenLabs API key.
[…] info: pipeline: starting voice pipeline…
[…] info: pipeline: answer writtenHow it works
Three models cover the three API stages, each a thin wrapper around a remote ML model with a fixed configuration:
model Stt(const openai_key: string) : RemoteStt {
backend = "openai"
api_key = |wrap<string>(openai_key)
base_url = ""
model = "whisper-1"
}
model Llm(const openai_key: string) : RemoteLlm {
backend = "openai"
api_key = |wrap<string>(openai_key)
base_url = ""
model = "gpt-4o"
system = "You are a helpful voice assistant. Answer briefly and clearly."
max_tokens = |wrap<u64>(256)
temperature = |wrap<f32>(0.7)
top_p = _
timeout = _
}
model Tts(const elevenlabs_key: string, const voice: string) : RemoteTts {
backend = "elevenlabs"
api_key = |wrap<string>(elevenlabs_key)
base_url = ""
model = "eleven_multilingual_v2"
voice = voice
}The startup treatment instantiates all three models and wires the pipeline as a straight sequence of sub-treatments:
model stt: Stt(openai_key=openai_key)
model llm: Llm(openai_key=openai_key)
model tts: Tts(elevenlabs_key=elevenlabs_key, voice=elevenlabs_voice)
read: readLocal(path=input_file)
startup.trigger -> read.trigger
sttTranscribe[stt=stt]()
read.data -> sttTranscribe.audio
llmRespond[llm=llm]()
sttTranscribe.transcript -> llmRespond.question
ttsSpeak[tts=tts]()
llmRespond.answer -> ttsSpeak.text
write: writeLocal(path=output_file)
ttsSpeak.audio -> write.data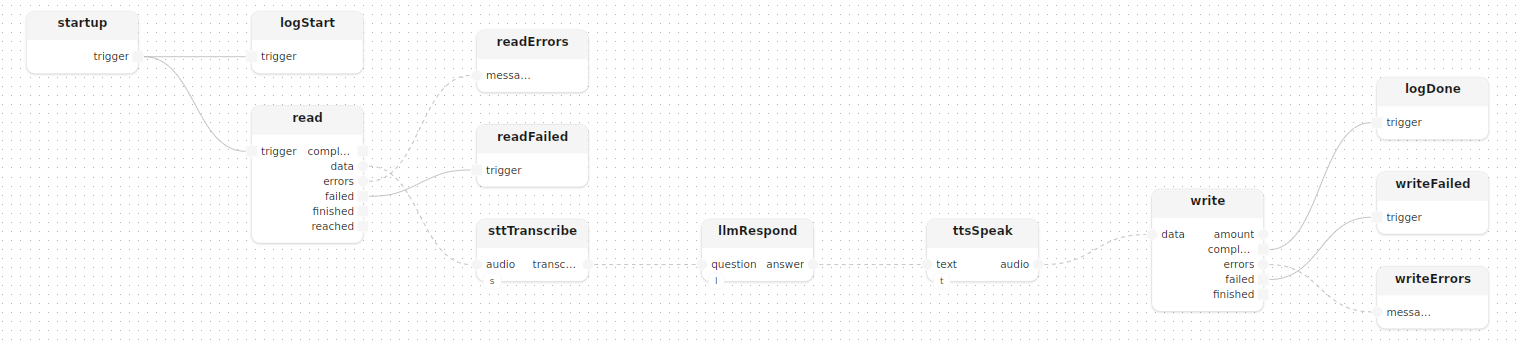
Block/Stream boundary at STT output
sttTranscribe[stt] sends the whole audio byte stream to transcribe (remote STT), which returns a Block<string>, one value for the whole audio file. The downstream llmRespond treatment expects a Stream<string> input, so stream<string>() bridges the two:
treatment sttTranscribe[stt: RemoteStt]()
input audio: Stream<byte>
output transcript: Stream<string>
{
transcribe[stt=stt]()
transcriptAsStream: stream<string>()
Self.audio -> transcribe.audio
transcribe.transcript -> transcriptAsStream.block,stream -> Self.transcript
}Prompt construction and streamed answer
llmRespond[llm] wraps each transcript string in a prompt template using entry and format, then calls chat from RemoteLlm, which streams response tokens back as they arrive:
treatment llmRespond[llm: RemoteLlm]()
input question: Stream<string>
output answer: Stream<string>
{
wrapEntry: entry(key="q")
fmt: format(format="User asked: {q}\nPlease answer helpfully.")
chat[llm=llm]()
Self.question -> wrapEntry.value,map -> fmt.entries,formatted -> chat.prompt,response -> Self.answer
}TTS output
ttsSpeak[tts] sends each response string straight to synthesize from RemoteTts, which emits audio bytes as a Stream<byte> written by writeLocal:
treatment ttsSpeak[tts: RemoteTts]()
input text: Stream<string>
output audio: Stream<byte>
{
synthesize[tts=tts]()
Self.text -> synthesize.text,audio -> Self.audio
}The output stream is written directly to the output file. The audio format (MP3 by default for ElevenLabs) is determined by the TTS backend. Each of the three sub-treatments keeps a clean Stream<T> in / Stream<T> out signature and handles its own error logging, so the stages stay independently replaceable.
Dependencies
[dependencies]
std = "0.10.1" # core flows, logging, data structures
fs = "0.10.1" # local file I/O
audio = "0.10.1" # audio decode / encode / resample
record = "0.10.1" # microphone capture
ml = "0.10.1" # LLM, STT, TTS and local model inference