Meeting Summary Service
Source: 10_meeting_summary_service
An HTTP server that accepts raw audio uploads, transcribes them with the ElevenLabs Scribe API, generates a structured meeting summary with Claude Sonnet, and streams the summary back as the HTTP response. Each request is handled in its own track; the server processes multiple simultaneous uploads without any explicit thread management.
Running
melodium run 10_meeting_summary_service/Compo.toml \
--anthropic_key sk-ant-... \
--elevenlabs_key el-...anthropic_key is an Anthropic API key. elevenlabs_key is an ElevenLabs API key.
$ curl -X POST http://127.0.0.1:8080/summarise \
--data-binary @meeting.wav \
-H "Content-Type: audio/wav"
## Meeting Summary
**Overview:** …
**Key decisions:**
- …
**Action items:**
- …How it works
Two models wrap the remote STT and LLM backends:
model Stt(const elevenlabs_key: string) : RemoteStt {
backend = "elevenlabs"
api_key = |wrap<string>(elevenlabs_key)
base_url = ""
model = "scribe_v1"
}
model Llm(const anthropic_key: string) : RemoteLlm {
backend = "anthropic"
api_key = |wrap<string>(anthropic_key)
base_url = ""
model = "claude-sonnet-4-6"
system = "You are an expert meeting assistant. Given a raw transcript, produce a concise, structured summary with: key decisions, action items, and a one-paragraph overview."
max_tokens = 512
temperature = 0.4
top_p = _
timeout = _
}Stt uses the ElevenLabs scribe_v1 model. Llm uses Claude Sonnet with a structured summarisation system prompt and a lower temperature (0.4) to produce focused, consistent output. All three models, including the HttpServer, are instantiated at startup:
treatment main(
const anthropic_key: string,
const elevenlabs_key: string,
const port: u16 = 8080
)
model server: HttpServer(host=|from_ipv4(|localhost_ipv4()), port=port)
model stt: Stt(elevenlabs_key=elevenlabs_key)
model llm: Llm(anthropic_key=anthropic_key)
{
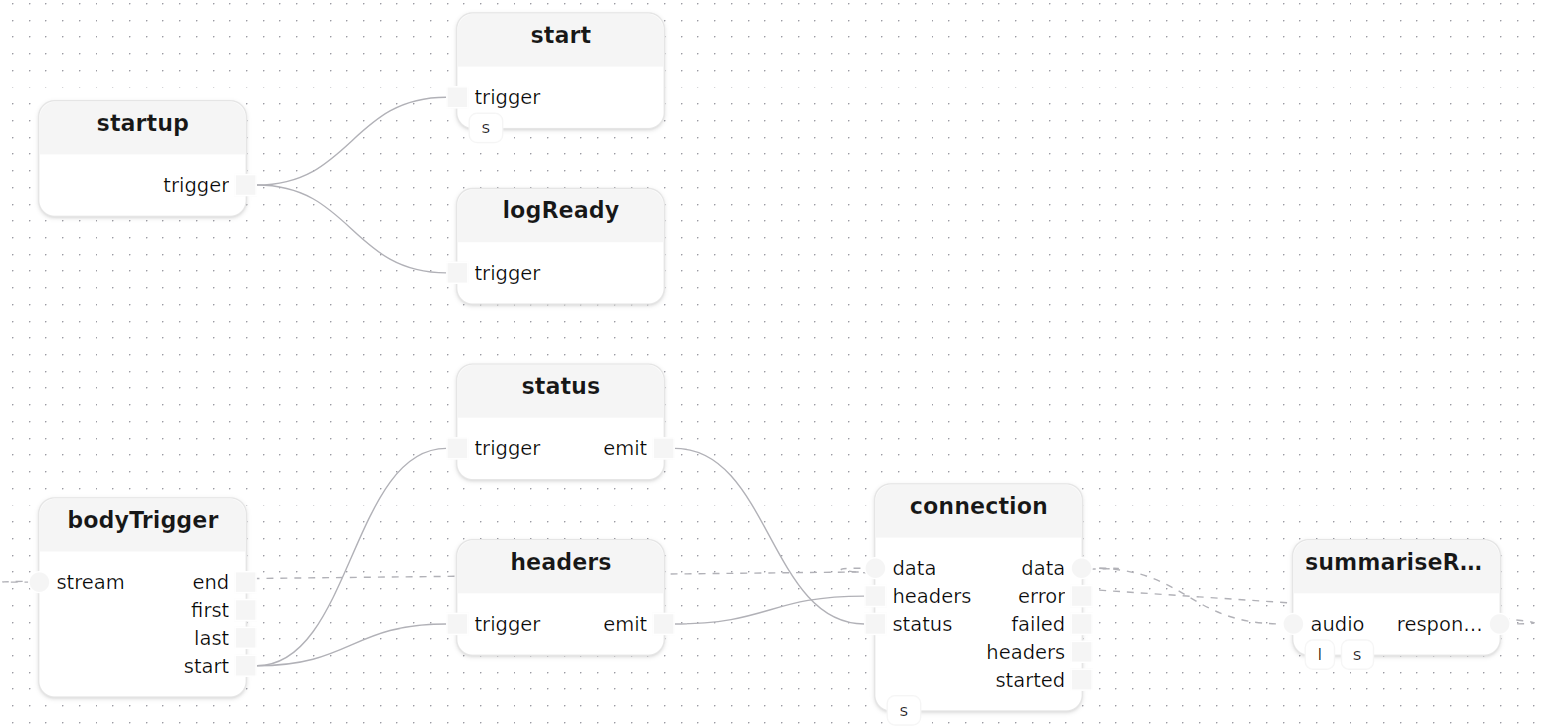
startup()
start[http_server=server]()
logReady: logInfoMessage(label="service", message="meeting summary service ready")
startup.trigger -> start.trigger
startup.trigger -> logReady.trigger
connection[http_server=server](method=|post(), route="/summarise")
status: emit<HttpStatus>(value=|ok())
headers: emit<StringMap>(value=|map([]))
bodyTrigger: trigger<byte>()
connection.data -> bodyTrigger.stream,start --> status.trigger,emit -> connection.status
bodyTrigger.start --------> headers.trigger,emit -> connection.headers
summariseRequest[stt=stt, llm=llm]()
connection.data -> summariseRequest.audio,response -> connection.data
}
Per-request pipeline
The summariseRequest sub-treatment handles everything for one request:
treatment summariseRequest[stt: RemoteStt, llm: RemoteLlm]()
input audio: Stream<byte>
output response: Stream<byte>
{
transcribe[stt=stt]()
transcriptStream: stream<string>()
sttFailed: logErrorMessage(label="stt", message="transcription failed")
sttError: logError(label="stt")
Self.audio -> transcribe.audio
transcribe.transcript -> transcriptStream.block,stream -> buildSummaryPrompt.transcript
transcribe.failed -> sttFailed.trigger
transcribe.error -> sttError.message
buildSummaryPrompt()
chat[llm=llm]()
encode()
llmErrors: logErrors(label="llm")
buildSummaryPrompt.prompt -> chat.prompt,response -> encode.text,data -> Self.response
chat.error -> llmErrors.messages
}transcribe returns a Block<string>. The stream<string>() adapter converts it to a Stream<string> so it can flow into buildSummaryPrompt, which wraps the raw transcript in a prompt template using entry and format:
treatment buildSummaryPrompt()
input transcript: Stream<string>
output prompt: Stream<string>
{
wrapEntry: entry(key="t")
fmt: format(format="Here is the meeting transcript:\n\n{t}\n\nPlease produce a structured meeting summary.")
Self.transcript -> wrapEntry.value,map -> fmt.entries,formatted -> Self.prompt
}chat from RemoteLlm returns a Stream<string> of response tokens, which are encoded and forwarded directly into connection.data. Summary tokens appear in the HTTP response as they are generated.

Video Explanation
Dependencies
[dependencies]
std = "0.10.1" # core flows, logging, data structures
http = "0.10.1" # HTTP server and client
net = "0.10.1" # IP address helpers
encoding = "0.10.1" # UTF-8 encode / decode
ml = "0.10.1" # LLM, STT, TTS and local model inference