LLM Chat Server
An HTTP server that accepts plain-text prompts via POST /chat and streams the LLM response token by token back to the caller. The LLM connection is declared as a model and shared across all concurrent requests.
Running
melodium run 01_text_llm_chat/Compo.toml --api_key sk-... --model claude-sonnet-4-6api_key here is an Anthropic API key, since model is set to a Claude model.
$ curl -X POST http://127.0.0.1:8080/chat -d "What is Mélodium?"
Mélodium is a dataflow programming language…How it works
ChatLlm wraps RemoteLlm with a fixed backend, system prompt, and token limit:
model ChatLlm(const api_key: string, const model: string) : RemoteLlm {
backend = "anthropic"
api_key = |wrap<string>(api_key)
base_url = ""
model = model
system = "You are a helpful assistant. Answer concisely."
max_tokens = 512
temperature = _
top_p = _
timeout = _
}The backend field selects the provider ("anthropic", "openai", etc.); switching providers means only changing backend and model in the model definition. The rest of the pipeline is unaffected.
Two models are instantiated at startup: the HttpServer and ChatLlm. The startup treatment fires once when the program launches, and its trigger is forwarded to both start (which binds the server socket) and the startup log line:
treatment main(
const api_key: string,
const model: string = "claude-sonnet-4-6",
const port: u16 = 8080
)
model server: HttpServer(host=|from_ipv4(|localhost_ipv4()), port=port)
model llm: ChatLlm(api_key=api_key, model=model)
{
startup()
start[http_server=server]()
logStarted: logInfoMessage(label="server", message="LLM chat server started")
startup.trigger -> start.trigger
startup.trigger -> logStarted.trigger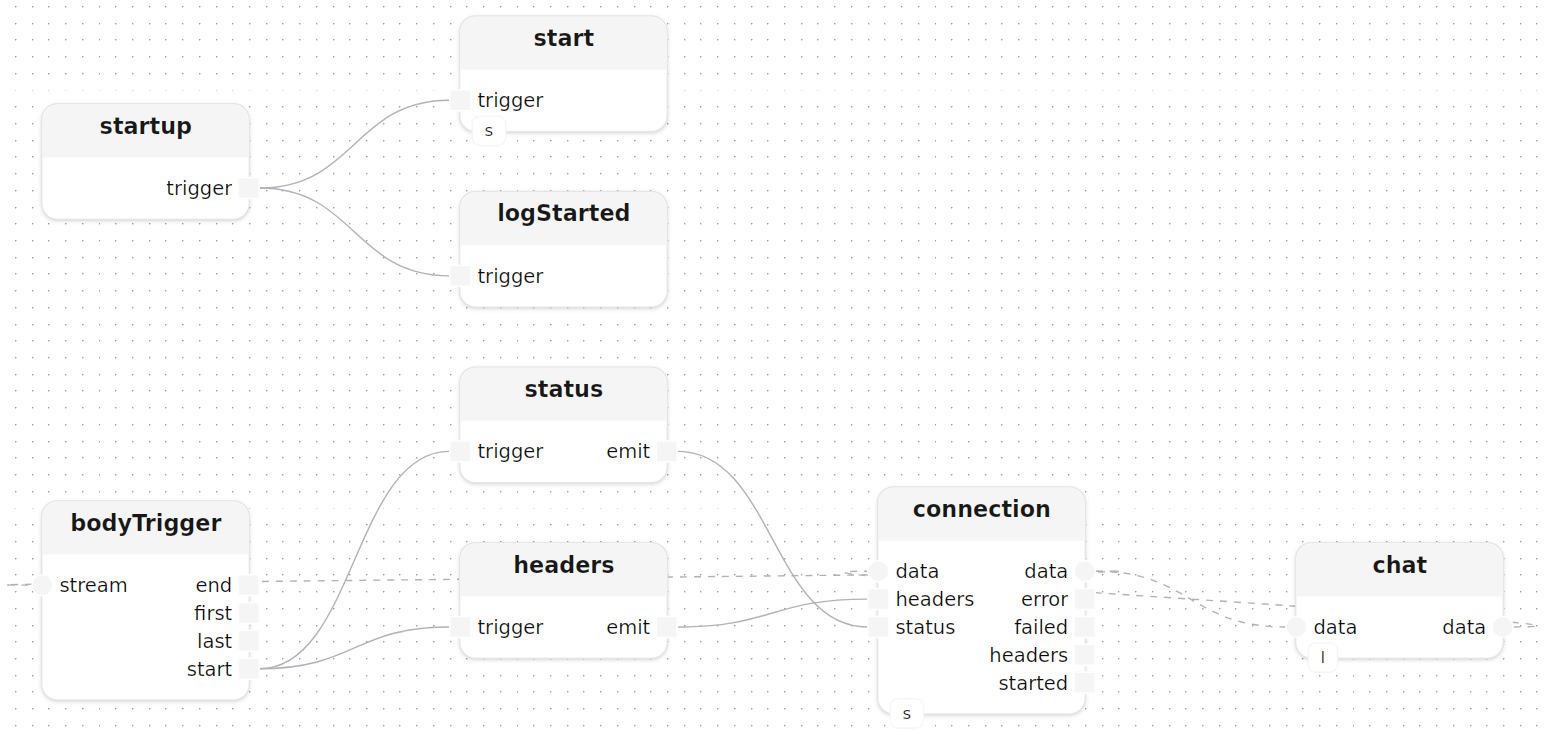
Sending status and headers before the body is read
Each connection needs a status and headers sent before the response body can start streaming. bodyTrigger fires as soon as the first byte of the request arrives, and that single Block<void> signal fans out to both status and headers in parallel via emit and trigger:
connection[http_server=server](method=|post(), route="/chat")
status: emit<HttpStatus>(value=|ok())
headers: emit<StringMap>(value=|map([]))
bodyTrigger: trigger<byte>()
connection.data -> bodyTrigger.stream,start --> status.trigger,emit -> connection.status
bodyTrigger.start --------> headers.trigger,emit -> connection.headers
chat[llm=llm]()
connection.data -> chat.data,data -> connection.dataThe chat sub-treatment
Each incoming connection is handled by the chat sub-treatment, which is a straight three-step pipeline:
treatment chat[llm: RemoteLlm]()
input data: Stream<byte>
output data: Stream<byte>
{
decode()
llmStream[llm=llm]()
encode()
llmPrompt: logInfos(label="llm")
llmErrors: logErrors(label="llm")
Self.data -> decode.data,text -> llmStream.prompt,token -> encode.text,data -> Self.data
decode.text -> llmPrompt.messages
llmStream.error -> llmErrors.messages
}decodeconverts raw request bytes to UTF-8 textllmStreamsends the text as a prompt and emits tokens as aStream<string>as they arriveencodeconverts each token back to bytes and forwards them directly intoconnection.data
Because llmStream emits tokens as a stream, they reach the HTTP response as they are produced, with no buffering and no explicit async logic.
Prompt text and LLM errors are independently forwarded to loggers (logInfos, logErrors) via separate connections, without interrupting the token stream.
Video Explanation
Dependencies
[dependencies]
std = "0.10.1" # core flows, logging, data structures
http = "0.10.1" # HTTP server and client
net = "0.10.1" # IP address helpers
encoding = "0.10.1" # UTF-8 encode / decode
ml = "0.10.1" # LLM, STT, TTS and local model inference