Realtime Voice Assistant
Source: 11_realtime_voice_assistant
A voice assistant that transcribes microphone audio with local Whisper and sends each segment to a language model for a response. Two entrypoints let you choose between a remote LLM (streaming tokens) or a fully local Mistral 7B (no API key needed).
Running
With a remote LLM (GPT-4o):
melodium run 11_realtime_voice_assistant/Compo.toml --openai_key sk-...openai_key is an OpenAI API key.
Fully local (no API key, requires ~14 GB RAM):
melodium run 11_realtime_voice_assistant/Compo.toml localonly[…] info: assistant: ready, speak into the microphone
[…] info: you: What time is it in Tokyo?
[…] info: assistant: Tokyo is in Japan Standard Time (JST), which is UTC+9…How it works
Both entrypoints share the same Whisper loading sequence and models:
model WhisperHub() : HfHub { repo_id = "openai/whisper-tiny" }
model Asr() : Whisper {}The difference lies only in which LLM backend is used downstream.
main: local Whisper + remote LLM
The remote LLM is a RemoteLlm model configured for GPT-4o with a short, concise system prompt:
model RemoteAssistant(const openai_key: string) : RemoteLlm {
backend = "openai"
api_key = |wrap<string>(openai_key)
base_url = ""
model = "gpt-4o"
system = "You are a concise voice assistant. Answer in plain text, one short paragraph."
max_tokens = |wrap<u64>(256)
temperature = |wrap<f32>(0.6)
top_p = _
timeout = _
}main fetches and loads Whisper first, then only starts recording once loading has completed:
treatment main(const openai_key: string)
model whisperHub: WhisperHub()
model asr: Asr()
model llm: RemoteAssistant(openai_key=openai_key)
{
fetchAsr: fetch[hub=whisperHub]()
loadAsr: loadWhisper[whisper=asr]()
startup.trigger -> fetchAsr.trigger
fetchAsr.safetensors -> loadAsr.safetensors
fetchAsr.tokenizer -> loadAsr.tokenizer
record: recordMono(device=_, sample_rate=_)
asrDecode: decode[whisper=asr]()
loadAsr.loaded -> record.trigger
loadAsr.loaded -> asrDecode.ready
record.signal -> asrDecode.audio
}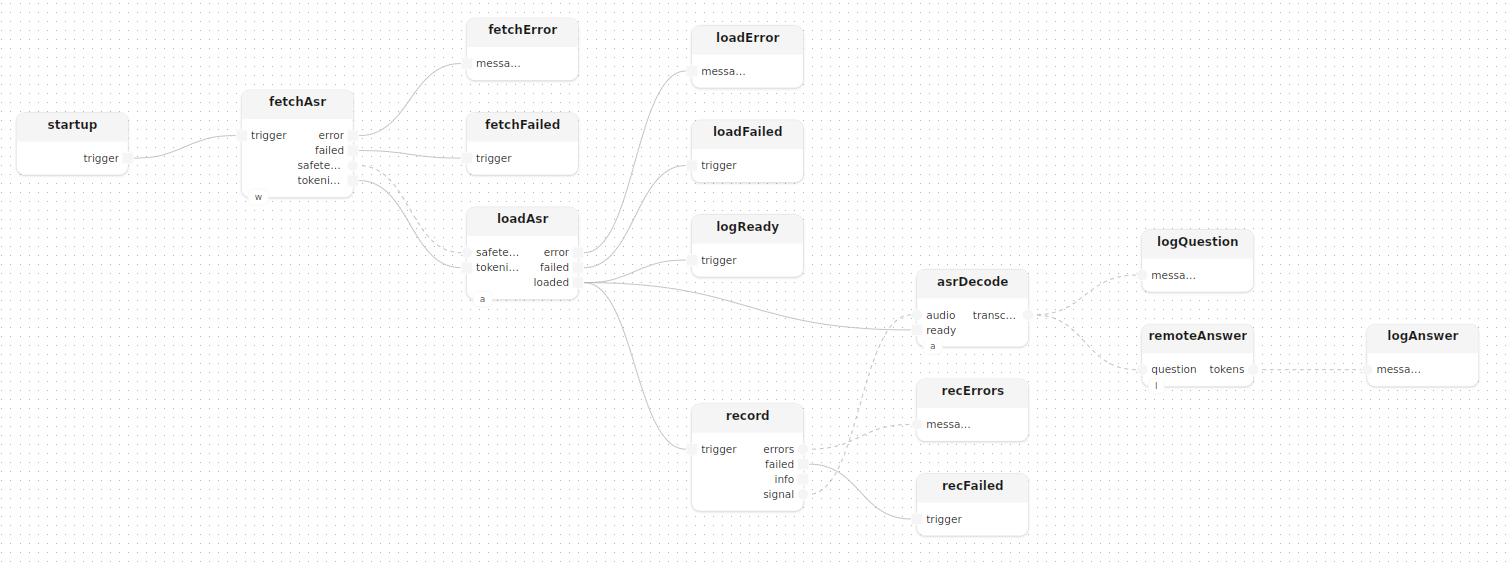
Each transcribed segment fans out to two consumers simultaneously:
asrDecode.transcribed -> logQuestion.messages
asrDecode.transcribed -> remoteAnswer.questionremoteAnswer[llm: RemoteLlm] wraps the question in "[Question] {q}" and calls llmStream, which emits tokens one by one as a Stream<string>, printed to the log in real time without waiting for the full response:
treatment remoteAnswer[llm: RemoteLlm]()
input question: Stream<string>
output tokens: Stream<string>
{
wrapEntry: entry(key="q")
fmt: format(format="[Question] {q}")
llmStream[llm=llm]()
Self.question -> wrapEntry.value,map -> fmt.entries,formatted -> llmStream.prompt,token -> Self.tokens
}localonly: local Whisper + local Mistral
The localOnly entrypoint adds two more models for a fully local Mistral 7B backend:
model MistralHub() : HfHub { repo_id = "mistralai/Mistral-7B-v0.1" }
model LocalLlm() : Mistral {
temperature = 0.7
top_p = 0.9
max_new_tokens = 200
}Both Whisper and Mistral are fetched in parallel from startup, and load independently:
treatment localOnly()
model whisperHub: WhisperHub()
model mistralHub: MistralHub()
model asr: Asr()
model llm: LocalLlm()
{
fetchAsr: fetch[hub=whisperHub]()
fetchLlm: fetch[hub=mistralHub]()
loadAsr: loadWhisper[whisper=asr]()
loadLlm: loadMistral[mistral=llm]()
startup.trigger -> fetchAsr.trigger
startup.trigger -> fetchLlm.trigger
fetchAsr.safetensors -> loadAsr.safetensors
fetchAsr.tokenizer -> loadAsr.tokenizer
fetchLlm.safetensors -> loadLlm.safetensors
fetchLlm.tokenizer -> loadLlm.tokenizer
}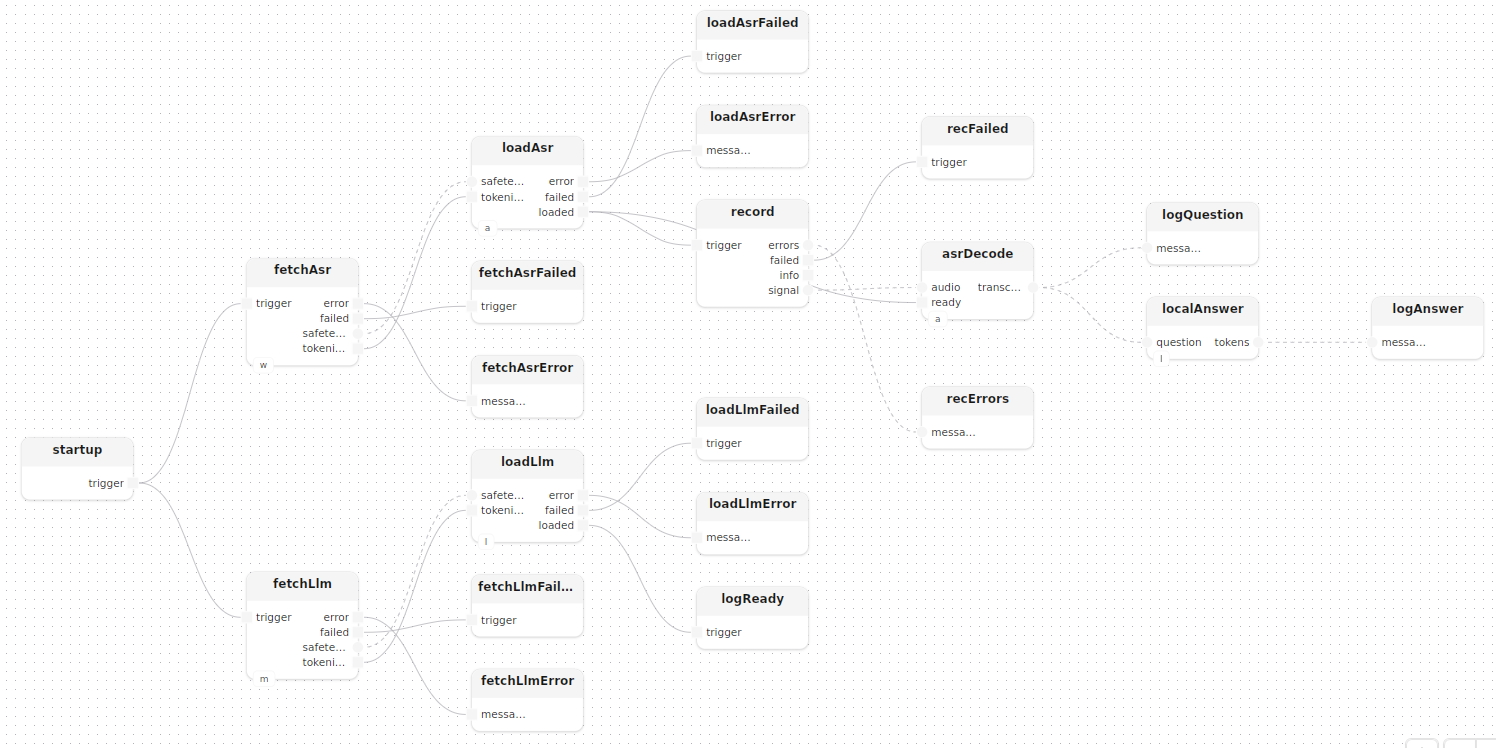
Recording starts as soon as Whisper is loaded (loadAsr.loaded), which may happen before Mistral finishes loading; each transcribed segment is still handed to localAnswer[llm: Mistral], which formats it in Mistral’s instruction style and calls generate instead of llmStream:
treatment localAnswer[llm: Mistral]()
input question: Stream<string>
output tokens: Stream<string>
{
wrapEntry: entry(key="q")
fmt: format(format="[INST] {q} [/INST]")
generate[mistral=llm]()
Self.question -> wrapEntry.value,map -> fmt.entries,formatted -> generate.prompt,generated -> Self.tokens
}Shared interface, different backends
remoteAnswer and localAnswer both expose the same question: Stream<string> in / tokens: Stream<string> out interface, so the fan-out and logging logic in each entrypoint is identical. The entrypoint does not know or care which one it calls; swapping backends is purely a model-level concern.
Dependencies
[dependencies]
std = "0.10.1" # core flows, logging, data structures
audio = "0.10.1" # audio decode / encode / resample
record = "0.10.1" # microphone capture
ml = "0.10.1" # LLM, STT, TTS and local model inference