Speech Transcription
Source: 02_speech_transcription
Transcribes audio to text using a local Whisper model downloaded automatically from Hugging Face on first run. Two entrypoints: main for live microphone input, fromfile for transcribing an existing audio file.
Running
Live transcription from the microphone:
melodium run 02_speech_transcription/Compo.tomlTranscribe an audio file:
melodium run 02_speech_transcription/Compo.toml fromfile -- --input_file speech.wavExpected output:
[…] info: transcription: Hello, this is a test.
[…] info: transcription: The model is running locally.How it works
Two models are declared at the top of each entrypoint:
model Hub() : HfHub { repo_id = "openai/whisper-tiny" }
model Speech() : Whisper {}Hub points to the HfHub repository for Whisper tiny. Speech is an empty Whisper model configuration; default parameters are used.
Model loading sequence
The connections enforce that audio capture only starts once the model is ready:
treatment main(const output: string = "transcription.txt")
model hub: Hub()
model whisper: Speech()
{
startup()
fetch[hub=hub]()
load[whisper=whisper]()
decode[whisper=whisper]()
record: recordMono(device=_, sample_rate=_)
log: logInfos(label="transcription")
write: writeTextLocal(path=output, append=true)
startup.trigger -> fetch.trigger
fetch.safetensors -> load.safetensors
fetch.tokenizer -> load.tokenizer
load.loaded -> decode.ready
load.loaded -> record.trigger
record.signal -> decode.audiostartup triggers fetch, which downloads weights and tokenizer; load initialises the model; load.loaded simultaneously gates both decode.ready and the audio source. No synchronisation primitive is needed; the dataflow itself enforces the ordering.
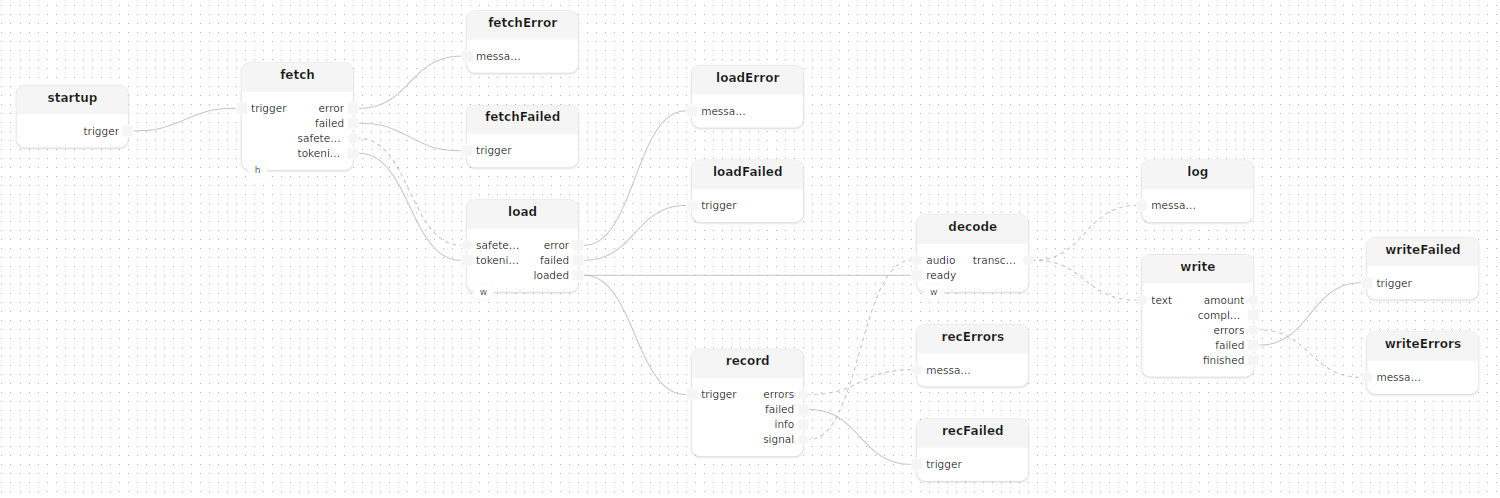
Fan-out to log and file
Once Whisper produces a transcribed segment, it is forwarded to two outputs at once using the --> double-arrow fan-out:
decode.transcribed --> log.messages
decode.transcribed --> write.text
}Both operations run concurrently.
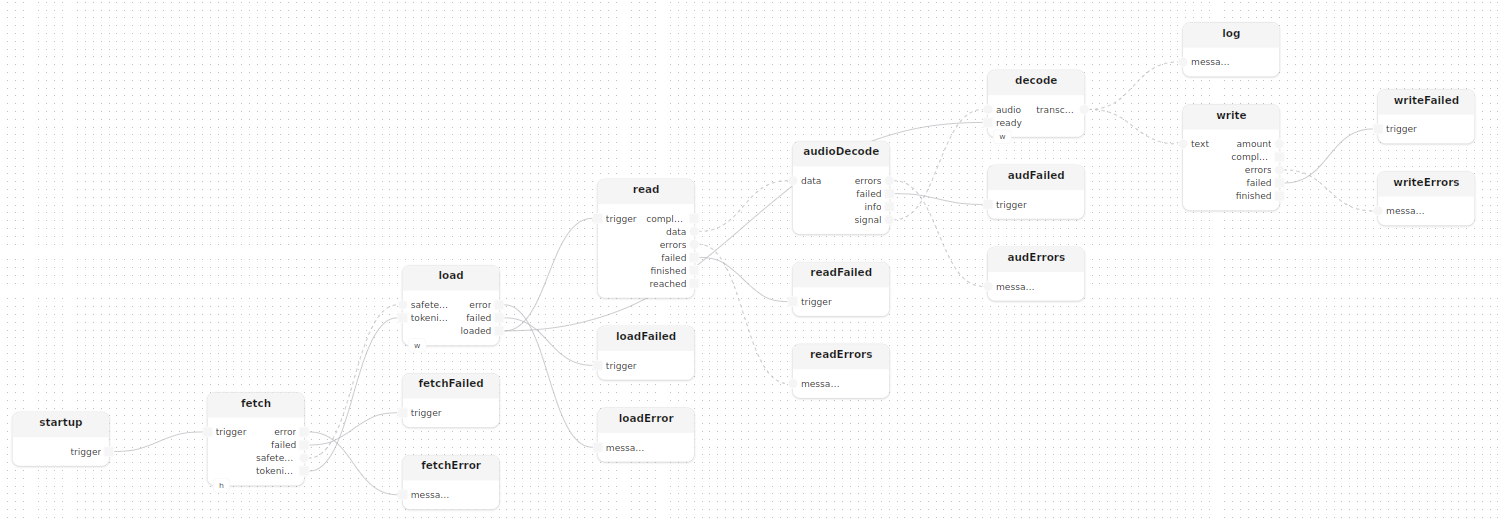
fromfile entrypoint
The fromFile entrypoint replaces recordMono with readLocal and decodeMono:
treatment fromFile(
const input_file: string,
const output: string = "transcription.txt"
)
model hub: Hub()
model whisper: Speech()
{
startup()
fetch[hub=hub]()
load[whisper=whisper]()
decode[whisper=whisper]()
read: readLocal(path=input_file)
audioDecode: decodeMono(hint="wav")
log: logInfos(label="transcription")
write: writeTextLocal(path=output, append=false)
startup.trigger -> fetch.trigger
fetch.safetensors -> load.safetensors
fetch.tokenizer -> load.tokenizer
load.loaded -> decode.ready
load.loaded -> read.trigger
read.data -> audioDecode.data
audioDecode.signal -> decode.audio
decode.transcribed --> log.messages
decode.transcribed --> write.text
}The decodeMono(hint="wav") treatment handles container format detection transparently; the same pipeline works for WAV, MP3, FLAC, and other formats.
Dependencies
[dependencies]
std = "0.10.1" # core flows, logging, data structures
fs = "0.10.1" # local file I/O
audio = "0.10.1" # audio decode / encode / resample
record = "0.10.1" # microphone capture
ml = "0.10.1" # LLM, STT, TTS and local model inference